流域水文模型的分类(基于多源数据机器学习的区域水质预测方法研究)
Posted
篇首语:满堂花醉三千客,一剑霜寒十四洲。本文由小常识网(cha138.com)小编为大家整理,主要介绍了流域水文模型的分类(基于多源数据机器学习的区域水质预测方法研究)相关的知识,希望对你有一定的参考价值。
流域水文模型的分类(基于多源数据机器学习的区域水质预测方法研究)
摘 要:
随着社会经济快速发展和水资源系统复杂性的日益增强,我国水环境质量的演变逐渐呈现跨区域、多因素耦合影响的特点。围绕大空间范围的水质预测问题,针对传统水质预测方法中对水文、气象及社会经济多因素考虑的不足,以广东省31个水质监测站在2008年到2016年间每周的水质等级数据为训练样本,选取降雨、蒸发和气温等气象指标以及GDP、总人口数、人口密度等社会经济指标为预测参数,运用支持向量机、决策树以及人工神经网络等机器学习技术,建立区域水质等级的预测模型。结果表明,机器学习方法可融合气象和社会经济等多源的、不同时空尺度的数据,对水质等级进行预测。其中,基于随机森林的预测模型表现性能最佳,预测准确率达到77.11%;基于支持向量机的预测模型次之,预测准确率达到74.99%。与现有的水质预测方法相比,该方法的计算速度快、不需要提取数据的统计特征、操作简单、能够分析社会经济因素对水质的影响,更容易在水环境治理中使用。
关键词:
区域水质预测;气象指标;社会经济因素;多源数据机器学习;水质;水环境;人工神经网络;机器学习技术;
作者简介:
李雪清(1996—),女,硕士研究生,主要从事人居环境机器学习研究。E-mail:lixueqing0509@163.com;
*郑航(1982—),男,副教授,博士,主要从事水资源管理与水权分配研究。E-mail:zhenghang00@163.com;
基金:
国家自然科学基金项目“基于水能耦合的长距离调水工程优化调度理论与应用”(51909035);
国家自然科学基金项目“长江水科学研究联合基金”项目“长江流域生态补偿研究”(U2040206);
引用:
李雪清,郑航,刘悦忆,等.基于多源数据机器学习的区域水质预测方法研究[J]. 水利水电技术(中英文),2021,52( 11):152⁃163.
LI Xueqing, ZHENG Hang, LIU Yueyi,etal. Multisource data machine learning⁃based study on method for regional water quality prediction [J]. Water Resources and Hydropower Engineering,2021,52(11):152⁃163.
0 引 言
随着社会经济发展和人类排污活动的增加,水体污染已经成为制约我国社会可持续发展和人民优质生活追求的重要因素。然而,随着地区之间社会经济联系的不断加强以及气候变化的影响,我国水环境演变呈现跨区域、多因素耦合影响的复杂变化,单一河段或流域的水质预测和水环境治理已逐渐不能满足要求,亟需大空间范围、多影响因素的水质综合预测。
水质预测是在一定空间范围内识别控制单元水质指标或水环境质量状况的时间变化特征及其对水文、气象以及污染源等影响因素的响应关系。目前常用的水质预测方法主要可分为两类,一类是数值模拟方法,一类是数理统计方法。数值模拟方法主要是基于质量守恒定律和力学方程,建立水体污物产生与迁移的数学模型,预测水域内的水质状况变化。根据计算原理的不同,数值模拟可分为流域水文-水质模型和河流水动力-水质模型。其中,流域水文-水质模型通过模拟流域或区域的降雨和产汇流过程及其伴生的污染物产生和汇聚过程,解析水体污染在大空间尺度上的发生发展规律,预测在不同水文条件和下垫面变化条件下流域水质的变化情况。例如,张永勇将相邻闸坝间污染物平衡方程耦合进SWAT模型,建立了SWAT-QCmode并用遗传算法求解,研究了闸坝优化调度下温榆河流域的水量水质演变过程。河流水动力-水质模型则一般模拟某一河段或者河网的水动力演进过程以及污染物在水体中的迁移和输运过程,预测不同排污情景和工程调水措施下污染物沿河的时空分布变化。刘悦忆等基于淮河水动力学-水质模型,采用蒙特卡洛模拟方法对目标断面的水质概率分布和污染事故发生概率进行了预测。数值模拟方法的物理概念清晰,能够在机理层面客观地反应系统运行的实际情况,解析不同因素影响下流域或河流水量水质的变化规律,在水质管理中普遍采用。然而,由于水资源系统演变和污染物水化学过程的复杂性,水体污染物的迁移转化机理还不完全清楚,许多过程难以用确定性的数学方法描述,很多参数无法精准测量和率定,导致数值模拟的精确度不高。此外,数值模拟方法的计算量大,在大范围应用上具有一定的困难。
数理统计方法主要基于观测数据建立水质变化的统计相关模型,识别水质数据的时空分布特征、预测水质的变化趋势。例如,刘东君等采用基于灰色预测模型、趋势外推法和指数平滑法的最优加权组合预测模型,建立了北京永定河溶解氧(DO)浓度的预测模型,对2010年到2011年永定河官厅水库出口的DO值进行了预测。此外,有学者从影响水质状况的影响因子出发,建立水质与影响因子之间的多元相关关系,借助影响因子的变化来反映水质的变化趋势。例如,颜剑波等采用多元回归分析法,根据黄河上游潼关断面以及区间入河排污口的水量和水质,预测了下游三门峡断面的化学需氧量。张子安等采用系统聚类分析方法,以硅藻群种类及数量为指标对珠江流域北江水系的水质状况进行了预测。史复有等采用多元线性回归模型对黄河兰州段的耗氧有机污染物浓度进行了预测。总体来说,多元回归方法虽然能够在一定程度上反应水质变化的影响因素,计算量相对较低,但所需要的数据量大、对数据质量要求高,建模相对困难,在大空间范围进行水质多因素综合预测的难度仍然较大。
为弥补统计模型的不足,近年来有学者将机器学习等智能算法引入到区域水质预测中,如神经网络法、支持向量机、群体智能算法等。这些方法具有较强的非线性映射能力、学习能力和容错性,可以融合不同时空尺度的数据,计算效率高,为大空间范围的水质预测提供了便利。例如,王晓萍等建立了基于Levenberg Marguardt优化算法的反向传播神经网络模型,对钱塘江重点断面的PH值、总磷和化学需氧量等进行了预测。刘双印等提出了基于时间相似数据的支持向量机模型,对集约化河蟹养殖水域的溶解氧浓度进行了预测。过仲阳等建立了基于反向传播神经网络的水质动态预测模型,对上海地区第Ⅲ承压含水层的矿化度变化进行了预测。NAJAH等分别运用线性回归模型、多层感知器神经网络和径向基函数神经网络建立了马来西亚Johor河的水质参数预测模型,预测了总溶解固体、浊度和导电性等指标的变化。CHEN等对比了10种水质预测模型(包括7种传统模型和3种基于机器学习的集成模型)的性能,发现决策树、随机森林和深度级联森林的预测性能优于其它7种传统模型。上述研究为机器学习方法在水质预测上的应用提供了有益探索。然而,现有研究大都关注单一水质指标,如PH值、化学需氧量、溶解氧等,缺乏对区域水文、气象以及社会经济因素的考虑,对区域水环境综合治理的支撑能力尚有不足。
针对上述问题,本研究采用广东省31个水质监测站2008—2016年每周的水质等级数据,分别运用支持向量机、随机森林、决策树、AdaBoost和深度学习人工神经网络5种方法,建立区域降雨量、气温、蒸发量、GDP、总人口数、城市污水排放量等9个指标与区域水质等级之间的关系,建立多因素融合的水质等级预测模型,分析不同种类机器学习方法在大空间范围水质预测上的性能表现。所建立的模型能够反映自然与社会经济因素在区域尺度上对水质变化的影响,可为区域水环境治理决策提供宏观支持。
1 方法及原理
1.1 支持向量机
支持向量机(Support Vector Machine, SVM)是一类可用于分类和回归的有监督机器学习模型,旨在多维空间中找到一个能将全部样本单元分成两类的最优平面,即超平面,如图1所示,这一平面使两类中距离最近的点的间距尽可能大,在间距边界上的点被称为支持向量(support vector)。决定间距分割的超平面位于间距的中间,表达式如下

式中,ω为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。在样本空间中,当ωTx+b为正时,支持向量机属于正类,当为负时,属于负类,由此实现分类的任务。
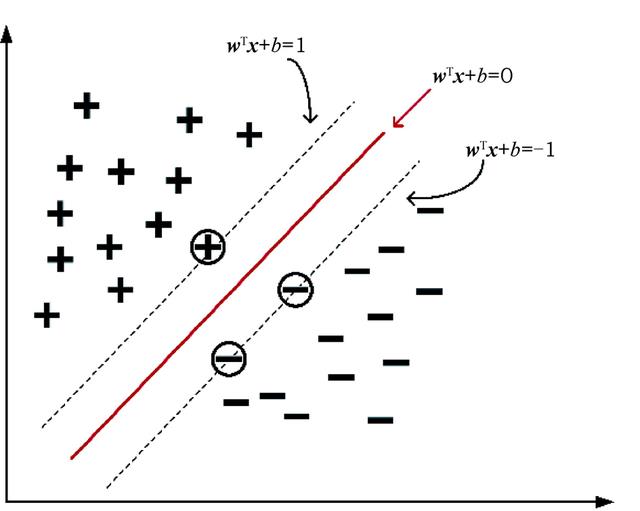
图1 支持向量机原理示意
1.2 决策树
决策树(Decision Tree, DT)是在数据挖掘中常用的分类模型,其基本思想是构造一棵可用于预测样本单元所属类别的树,如图2所示。一棵决策树由根结点、内部结点和叶结点组成。根结点包含样本全集,叶结点对应于决策结果,每个内部结点对应于一个属性测试。从根结点到每个叶结点的路径对应特定的判定测试序列,达到将样本分类的目的。
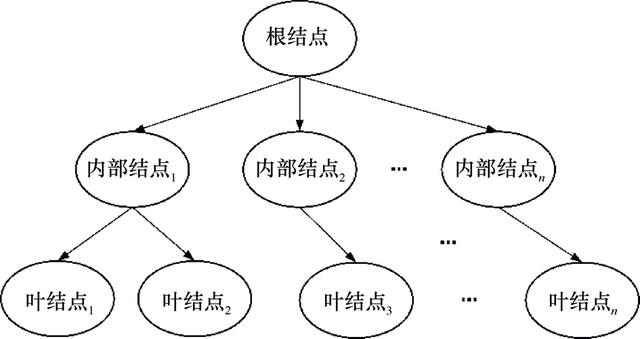
图2 决策树原理示意
1.3 集成学习
1.3.1 随机森林
随机森林(Random Forest, RF)以决策树为基础,进一步在决策树的训练过程中引入随机属性,其示意图如图3所示。基本思想是:利用bootstrap抽样从原始训练集抽取n个样本,每个样本的样本容量与原始训练集一样,对n个样本分别建立n个决策树模型,得到n种分类结果,最后根据投票决定最优分类。
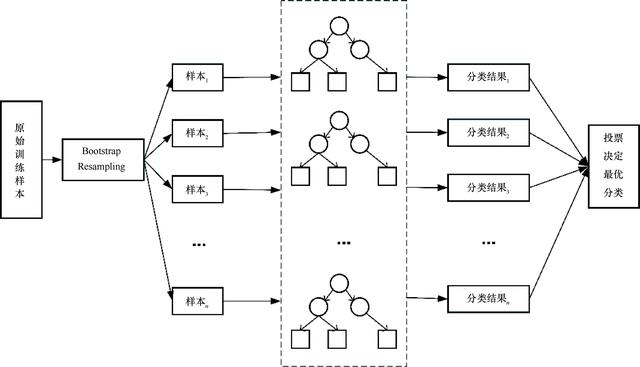
图3 随机森林原理
1.3.2 AdaBoost
AdaBoost是集成学习算法最著名的代表之一,其原理是:(1)先从初始训练集训练一个基学习器,对训练样本分布进行调整,使先前基学习器判断错的训练样本在后续受到更多的关注;(2)基于调整后的样本分布再训练下一个基学习器;(3)如此重复进行,直至基学习器的数目达到预先设定的值T;(4)最终将T个基学习器进行加权结合,建立最终的预测模型。
1.4 人工神经网络
人工神经网络(Artificial Neural networks, ANN)源自对生物神经网络的仿真和模拟。其在分类任务的工作流程如图4所示,原始样本经输入层进入网络,经若干个隐藏层,通过激活函数输出所属类别。
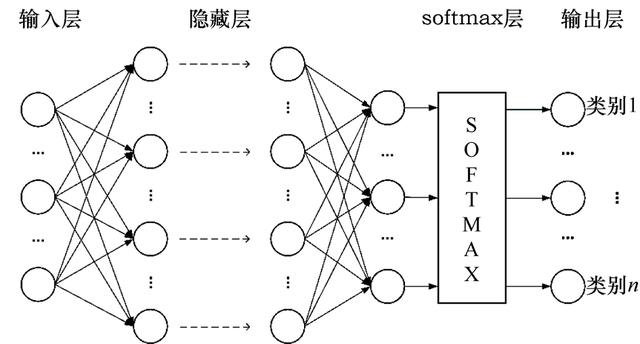
图4 神经网络在分类问题中的工作流程
2 水质预测模型计算流程
计算流程如图5所示,分为“数据预处理”和“模型训练与评估”两部分。
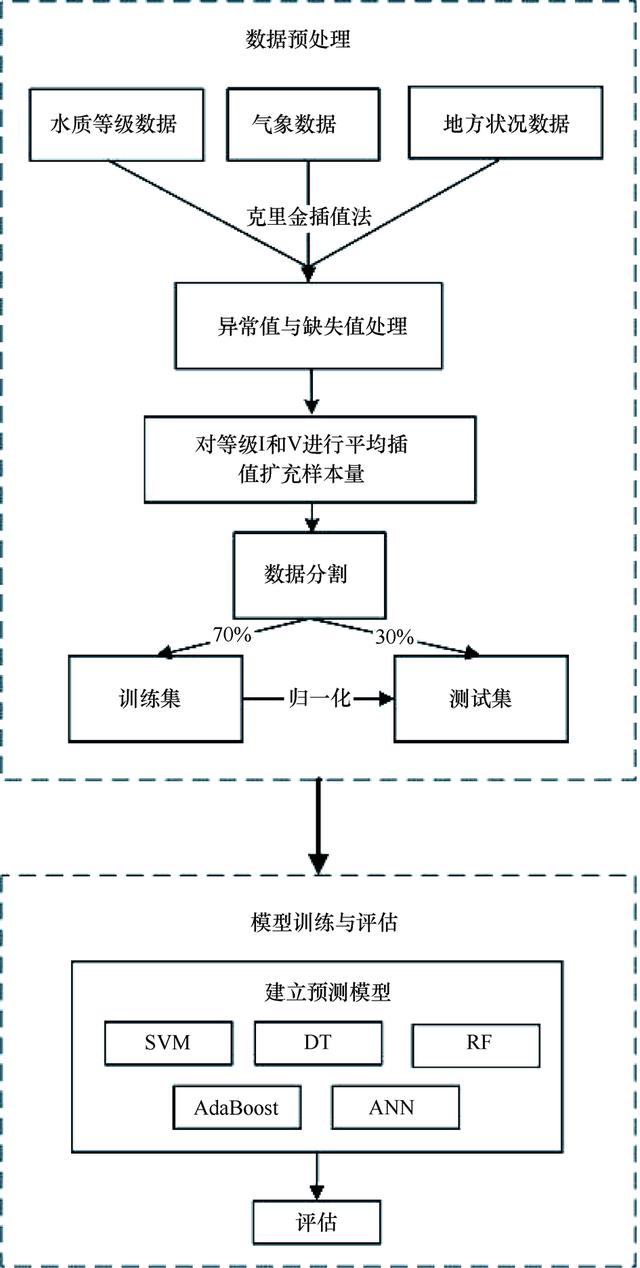
图5 水质预测模型计算流程
2.1 输入数据
以广东省生态环境公众网(http: //gdee.gd.gov.cn/)发布的广东省31个水质监测站2008年到2016年的周水质等级数据为研究对象。站点水质分为6个等级,如表1所列,等级越高表示水质质量越差。水质监测站点分布如图6所示。
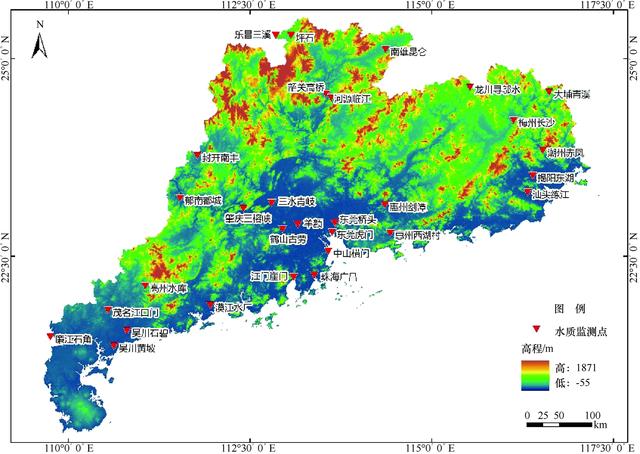
图6 广东省2008—2016年水质监测站分布
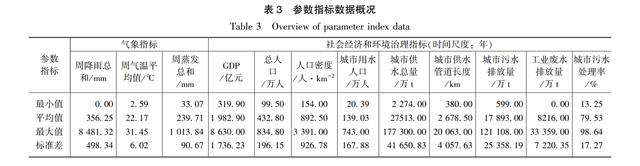
参数指标分为气象指标和社会经济指标两类。气象指标包括降雨、气温和蒸发,是水质预测中常用的指标。有研究表明,降雨、气温和蒸发等气象条件是驱动污染物迁移、传输和转化的重要因素,并采用机器学习方法研究了气象因素与区域水质之间的关系。本研究的气象数据采用中国气象数据网公布的广东省36个国家气象监测站的日尺度数据,气象监测站的分布如图7所示。除此之外,本研究采用GDP、总人口数、人口密度、城市用水人口、城市供水总量、城市供水管道长度、城市污水排放量、工业废水排放量以及城市污水处理率9个社会经济指标进行水质预测,如表2和表3所列。其中,GDP、总人口数以及人口密度,从区域经济发展规模上间接反映污染的整体排放强度;城市用水人口、城市供水总量、城市供水管道长度,从城市用水规模上间接反映污水的排放体量;城市污水排放量、工业废水排放量、城市污水处理率,直接影响一个区域的水质情况,是水质预测的重要指标。社会经济相关数据来自中国知网的大数据研究平台。
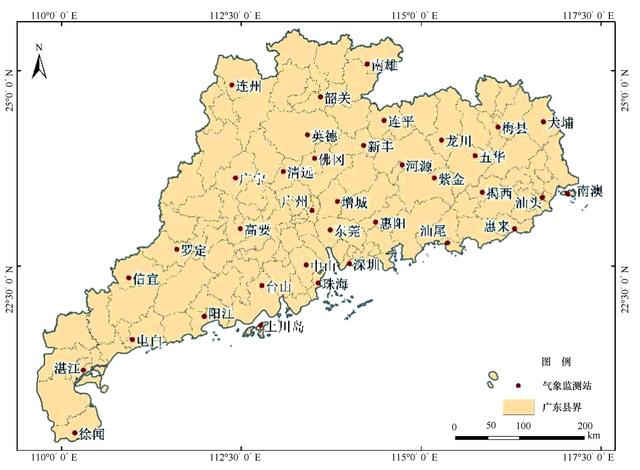
图7 广东省国家气象监测站分布

2.2 数据预处理
2.2.1 不同空间数据的处理
以水质监测站的地理位置为基准对气象数据及社会经济指标数据进行同化处理。由于气象数据采集点与水质监测站位于不同的位置,使用克里金插值法对气象数据进行插值,并提取各水质监测站处的气象数据。社会经济数据一般以行政区为界,因此,根据水质监测站所属的行政区将其社会经济信息匹配到各水质监测站。
2.2.2 不同时间尺度数据的处理
由于本文所采用的水质等级数据为周尺度,据此对气象以及社会经济数据进行处理。具体而言,对日尺度的气象数据,取一周内日降雨量总和作为周降雨量,取一周内日气温平均值作为周气温,取一周的日蒸发量总和作为周蒸发量;此外,年内每周的社会经济数据,取该年的年度社会经济数据。
2.2.3 水质数据样本的处理
为减小不同类别水质的训练样本量不均衡对预测模型性能的影响,对数据量较少的水质等级I和V的原始样本进行插值扩充。插值扩充之后,进行缺失值和异常值处理,剔除无效数据,得到11272组水质数据样本。选取样本数据的70%作为训练数据集,30%为测试数据集,样本数据量情况如表4所列。

2.2.4 归一化处理
采用最大最小值标准化方法进行归一化处理,如下
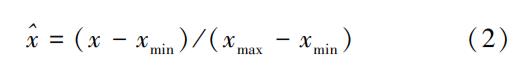
式中,xˆx^为归一化处理后的数据;x、xmin、xmax分别为原始数据、原始数据序列中的最小值和最大值。
2.3 模型训练与评估
分别运用支持向量机、决策树、随机森林、AdaBoost和深度学习人工神经网络建立水质预测模型,运用网格搜索的方法进行模型训练和参数优化,选择最优参数,将最优参数下的模型运用于测试数据集。采用测试数据集的预测准确率,进行各模型性能的比较,公式如下
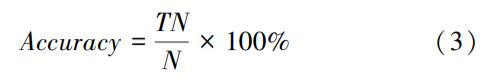
式中,Accuracy为准确率;N为样本总数;TN为正确分类的样本数量。
3 结果分析
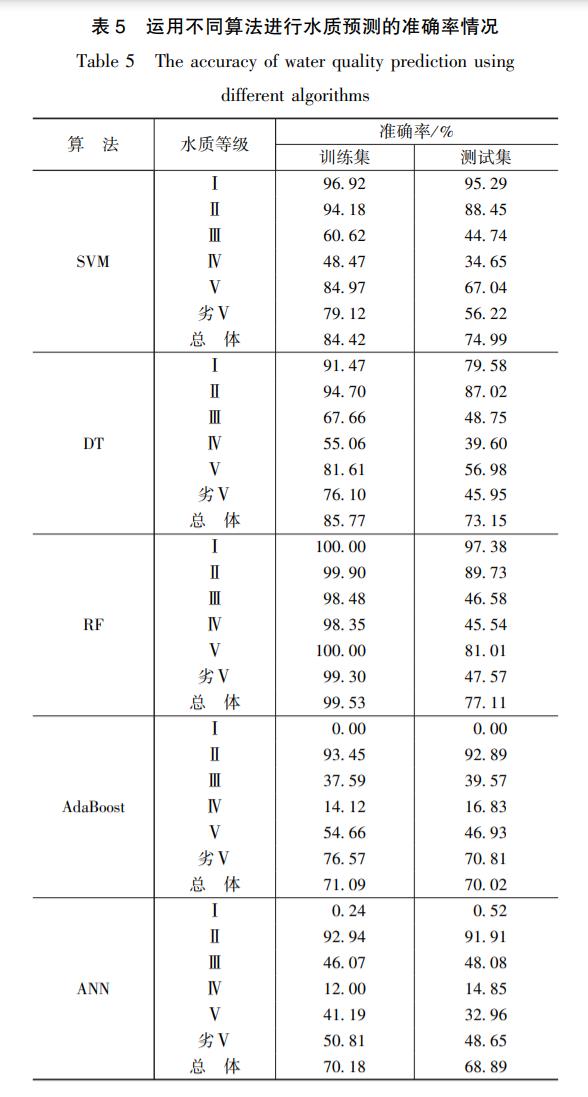
分别运用支持向量机(SVM)、决策树(DT)、随机森林(RF)、AdaBoost和人工神经网络(ANN)建立水质预测模型,各水质等级的预测准确率如表5所列。由表可知,人工神经网络模型性能最差,总体预测准确率为68.89%。支持向量机、决策树、随机森林和AdaBoost模型的性能较好,预测准确率均达到70%以上。其中,随机森林模型的性能最佳,预测准确率达到77.11%。
在上述模型中,选择准确率最高的前4种,即RF、SVM、DT和AdaBoost, 将由预测的水质等级和真实的水质等级形成的矩阵可视化,如图8所示。该热力图显示,4种模型对等级Ⅱ的预测准确度最高。与此同时,模型把其它等级误判为等级Ⅱ的比例最大,这是由于等级Ⅱ类别的训练样本量较大所致。此外,相邻矩阵的热力值总体表现为下三角颜色深于上三角,说明4种算法倾向于将较劣等级的水质样本误判为较优等级。
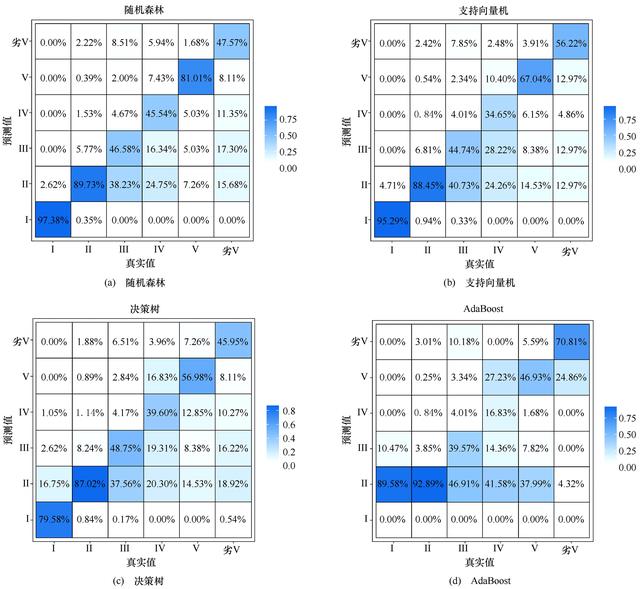
图8 预测分级与真实分级相邻矩阵热力图
运用表现性能最佳的随机森林预测模型,对2020年1—12月广东省的水质等级进行预测,结果如图9所示。由图9可知,在空间上,水质较差的区域主要集中在珠三角和粤西地区;在时间上,春季冬季枯水季节,污染较重,夏季秋季丰水季节,水质较好。
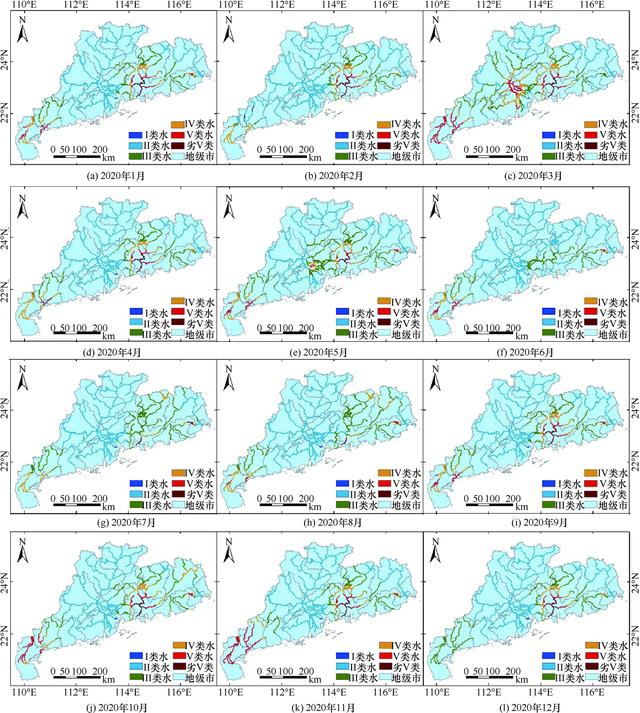
图9 广东省2020年1—12月水质等级预测分布
将预测值与2020年广东省的水质实测值进行比较,如图10所示。在图10中,横坐标为实测的水质等级,纵坐标为预测的水质等级,气泡大小表示对应的样本数量。由图10可知,实测值和预测值都为水质等级Ⅱ的样本数目最多,水质等级Ⅲ的被误判为等级Ⅱ的比例最大。
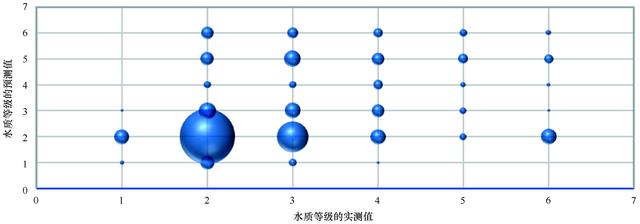
图10 2020年水质等级实测值与预测值对比
4 结果讨论
本文分别运用支持向量机(SVM)、决策树(DT)、随机森林(RF)、AdaBoost和人工神经网络(ANN),构建区域的水质预测模型,以水文、气象以及社会经济数据为输入,预测区域的水质等级。模型中表现性能最佳的为随机森林模型,预测准确率达到77.11%。其它除人工神经网络外,预测准确率均达到70%以上。与其他类似研究相比,本文所构建的模型可综合考虑气象、水文和社会及经济因素,对流域或区域尺度的地表水质等级进行预测。由于机器学习模型的数据依赖性和物理过程的黑箱性,方法在计算精度和结果的可解释性上具有一定的局限,尤其是在水质等级样本不均衡的情况下,计算精度有待提高。
水质等级Ⅱ与其他水质等级在训练样本量上的较大差异,是造成水质预测模型误差的一个重要原因。随机森林(RF)模型对于样本量较大的水质等级II预测准确率达到89.73%,对于样本量较少的水质等级IV,预测准确率为45.54%(见表5)。相应的,神经网络模型(ANN) 对于水质等级II的预测准确率达到91.91%,对于样本量较少的水质等级IV,预测准确率却仅为14.85%。可以看出,样本分布不均衡会影响机器学习模型的分类精度。相比神经网络模型(ANN),随机森林模型受样本不均衡的影响较小,适用性更强。
针对样本分布不均衡的问题,有学者采用多种输入组合的方法,探讨不同输入数据下各类别水质样本预测精度的变化,以寻求有效的输入参数。比如HO等采用氨氮(NH3-N)、BDO、COD、溶解氧(DO)、pH值和固体悬浮物(SS)指标作为输入,应用决策树机器学习方法,预测马来西亚Klang河流的水质等级。被预测的水质等级分为5类,其中水质等级Ⅴ级的样本量仅占总样本量的2%,而水质等级Ⅲ级和Ⅳ级的样本量占91%。模型预测结果对水质等级Ⅲ级和Ⅳ级的预测准确度基本达到70%以上,对水质等级Ⅴ级的预测准确率基本为0%。通过改变输入参数,舍弃pH值和氨氮指标,仅采用BOD、COD、DO和SS作为输入时,水质等级Ⅴ级的预测准确率可达到80%以上。与HO等研究相比,本文对原始样本进行平均插值扩充,一定程度上缓解了样本分布不均衡对预测模型性能的影响。随机森林模型对于样本量较少的水质等级Ⅳ级和Ⅴ级,预测准确率达到40%以上。未来可进一步增加或改变预测模型的输入变量,研究不同的输入变量组合对样本量较少的水质等级预测精度的变化,以寻求提高精度的方法。
此外,本研究采用GDP、总人口数、人口密度、城市用水人口、城市供水总量、城市供水管道长度、城市污水排放量、工业废水排放量以及城市污水处理率 9个指标,从区域经济发展规模、水资源利用水平以及污水排放体量3个层面,探究建立社会经济因素与区域水质之间定量关系的机器学习方法。结果表明机器学习方法在定量表达社会经济因素对水质的间接和非线性影响上,具有一定可用性。然而,由于社会经济和水资源系统的复杂性,影响水质变化的因素众多,比如地形、土壤、河道等影响水文产汇流特征的因素,耕地面积、化肥施用量、禽畜养殖量等影响面源污染的因素等等。进一步将这些因素加入到区域水质预测的机器学习模型中,增加模型的维度和数据量,对于提高模型的精度和可用性是有益的,是后续研究需要考虑的重要方向。
5 结 论
本研究应用广东省31个水质监测站2008—2016年的水质等级的周尺度数据,以3种气象指标和9种社会经济与环境治理指标为输入数据,分别运用支持向量机、决策树、随机森林、AdaBoost和人工神经网络,建立水质等级预测模型。主要结论如下:
(1)支持向量机、决策树、随机森林和AdaBoost模型均表现出较佳的性能,预测准确率均达到70%以上。其中,基于随机森林模型的性能最佳,准确率达77.11%,基于支持向量机的模型次之,预测准确率达到74.99%,表明机器学习方法可在区域尺度上综合考虑自然与社会因素对水质变化进行预测,可在宏观层面对区域水环境治理提供技术支撑。
(2)本文采用广东省31个水质监测站2008年到2016年的周水质等级数据作为研究对象,其中水质等级Ⅱ级的样本量占总样本量的60.34%,水质等级Ⅳ级却仅占5.56%。通过不同模型的对比发现,随机森林模型受样本不均衡的影响较小,适用性更强。
(3)随着气象、水文及水环境数据的不断丰富,流域水环境管理正在步入大数据时代,基于机器学习的水质预测和评估方法因其较好的非线性表达能力和较高的计算效率,将为流域水质管理提供越来越多的助力。然而,由于机器学习方法在物理原理和可解释性上的欠缺,未来还需在输入指标的选择、模型精度和敏感性上进行研究,以提高模型的适用性。
水利水电技术(中英文)
水利部《水利水电技术(中英文)》杂志是中国水利水电行业的综合性技术期刊(月刊),为全国中文核心期刊,面向国内外公开发行。本刊以介绍我国水资源的开发、利用、治理、配置、节约和保护,以及水利水电工程的勘测、设计、施工、运行管理和科学研究等方面的技术经验为主,同时也报道国外的先进技术。期刊主要栏目有:水文水资源、水工建筑、工程施工、工程基础、水力学、机电技术、泥沙研究、水环境与水生态、运行管理、试验研究、工程地质、金属结构、水利经济、水利规划、防汛抗旱、建设管理、新能源、城市水利、农村水利、水土保持、水库移民、水利现代化、国际水利等。

相关参考
水利枢纽模型(高考地理年年必考的“河流”为背景的试题思维模型)
...;南亚的印度河、恒河;西亚的底格里斯河和幼发拉底河流域内气候、河流的水文特征及开发整治、“一带一路”问题欧洲的莱茵河、多瑙河;南美洲的亚马孙河;非洲赞比西河、刚果河区域气候、河流水文特征分析;流域开发...
毕业模型(鱼和熊掌不可兼得?清华团队提出高准确率的可解释分类模型)
...之心专栏机器之心编辑部RRL的提出,不仅使得可解释规则模型能够适用于更大的数据规模和更广的应用场景,还为从业人员提供了一个更好的在模型复杂度和分类效果之间权衡的方式。现有的机器学习分类模型从性能和可解释性...
水文测站的分类(齐心战“疫”云上水周丨科普小讲堂,带你了解下有关水质的这些专业名词)
水质监测的意义水质监测是进行水资源保护科学研究的基础,是保护水资源的基本手段之一。水质监测长期收集大量的水质监测数据,可以研究出污染物质的来源、分布、迁移和变化的规律,对水质污染趋势作出预测。1什么是...
...个相对简单的算法,如何不能进行适当的剪枝就容易造成模型的过拟合。决策树算法也是当前很多集成学习算法的基础,集成算法的效果往往比单独使用决策树算法效果更好。关键词:决策树,集成学习1初识决策树决策树就是...
...成立,这是黄河干流上建成的第一座水文站,拉开了黄河流域以近代科学方法开展水文工作的序幕。如今的泺口水文站,是全国基本水文站和重点报汛站,开展有降水、水位、流量、泥沙、水质、水温、气温、冰情等观测项目,...
水分测定仪有哪些(自动水文监测站 水质水位监测系统 水文监测设备)
...自动监测站适用于水利部门对江河、湖泊、渠道、水库和流域内等水文参数进行实时远程自动监测,全面掌握水位、流量、流速、降水量、水质、水生态等参数、水雨情信息、洪水预警,实现对自然水环境科学监测、对基本水文...
数据的准确性(土耳其地震反思预警的重要性,如何搭建一个强大的数据预警模型)
...的心,如果你有兴趣,那就点赞关注吧,谢谢!数据预警模型系统简介通过土耳其地震,也认识到,人们急需一种数据预警系统,来提示人们规避风险,保障生命健康。总的来说,数据预警模型是一种基于大数据技术、机器学习...
...体的应用场景、是否有足够的数据进行分析、要建立预测模型、要有定义模型和训练模型的人员和工具......等等。为此,本文将具体阐述使用人工智能、深度学习和机器学习时,企业需要做的10项准备工作。-1-拥有足够多的数据...
...为程序控制的自动化操作。浮标系统通过浮体承载水质、水文、气象监测仪器,系统通过控制器发送指令监测仪器的测量运行,利用数采器实时采集监测仪器的监测数据,通过GPRS/CDMA传输数据,将数据回传到用户的控制部门,达...
...测系统拓扑图:水质监测系统功能及特点:1.通过水资源/水文相关行业规约、产品标准检测并获得相应产品资质,包括:水资源监测数据传输规约(SZY206-2016)、水资源监控设备基本技术条件(SL426-2008);水文监测数据传输规约...