数据采集技术有哪些(大数据平台的数据采集和集成技术和工具)
Posted
篇首语:没关系,天空越黑,星星越亮。本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据采集技术有哪些(大数据平台的数据采集和集成技术和工具)相关的知识,希望对你有一定的参考价值。
数据采集技术有哪些(大数据平台的数据采集和集成技术和工具)
本文主要介绍大数据平台构建中的数据采集和集成。在最早谈BI或MDM系统的时候,也涉及到数据集成交换的事情,但是一般通过ETL工具或技术就能够完全解决。而在大数据平台构建中,对于数据采集的实时性要求出现变化,对于数据采集集成的类型也出现多样性,这是整个大数据平台采集和集成出现变化的重要原因。
首先在这里表面一个观点,即:
不用期望通过单一的一个工具或技术来完成大数据采集和集成工作,而是需要针对数据采集的实时性需求,数据采集的类型,数据量大小等采用不同的方法和技术。
因此今天主要针对不同的大数据采集和集成场景做下说明。
结构化数据的数据实时同步复制
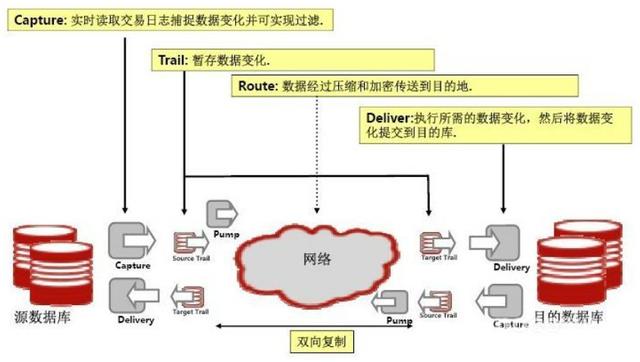
结构化数据库的实时同步复制,最早出现在类似异地双活,多中心基础设施架构的搭建中。而当前在很多数据库读写分离集群的场景中也经常用到。简单来说就是通过数据库同步复制,将读写分离,实现读集群本身的水平弹性扩展能力。
对于数据库实时同步和复制一定会谈到的两款商用产品就是Oracle GoldenGate和Quest SharePlex,具体的介绍网上也比较多,其核心特点就是支持异构数据库之间的实时数据同步和负责,而且对源数据库本身侵入性很小。
两个商用产品基本都是对各种数据库的Log日志文件进行分析,然后进行复制。
那对于这块如果要自研来实现有无可能?
对于Mysql来说由于采用Binlog日志方式,类似淘宝的Otter已经可以完整地实现数据库的实体同步复制。如果单纯是Oracle-Oracle数据库之间,我们也可以采用Oracle DataGuard或者Oracle Stream流复制技术进行复制,还有就是基于Oracle LogMiner进行redo log日志分析后进行两个数据库之间的同步。
因此关键问题还是在异构数据库之间的同步复制上。对于数据库复制,Oracle当前常用的解决方案主要有:
- oracle日志文件,比如LogMiner,OGG,SharePlex
- oracle CDC(Change Data Capture)
- oracle trigger机制,比如DataBus , SymmetricDS
- oracle 物化视图(materialized view)比如淘宝的yugong开源
在这些解决方案里面可以看到有开源的SymmetricDS解决方案,但是是基于触发器机制,侵入性还是相对较大。也有淘宝的yugong可以实现Oracle->mysql的全量或增量复制,但是基于增量物化视图方式,本身会影响到源库数据表的CUD操作。
而实际上最佳的解决方案仍然是基于log日志的实时同步复制,其核心思路包括三个步骤
在源库设置为记录日志或归档模式,源库首先能够记录下日志信息。实时的能够读取到日志信息,并对日志信息进行解析或适当转换映射,包括和目标库的适配。在目标数据库直接运行相应解析后的日志SQL语句,实现同步更新。由于Mysql本身提供可读性很强的Binlog日志,因此可以看到Mysql->Mysql,Mysql->Oracle的实时同步日志问题是可以得到很好解决的。而对于Oracle->Oracle也可以解决,较难的就是Oracle->Mysql或其它异构数据库,这里需要分析Oracle本身的redo log日志(当前Oracle提供有logminer工具),如果我们自己写一个解析包的话就需要对Oracle redo log结构有完整的了解。
而结合Oracle 流复制技术,我们可以考虑Oracle首先将变更信息写入到自己的AQ,然后我们从AQ订阅消息后直接处理或者写入到我们自己的消息队列或流处理软件,然后在流处理软件中完成相关的映射转换后写入到目标异构数据库中。
Sqoop和Flume数据采集和集成
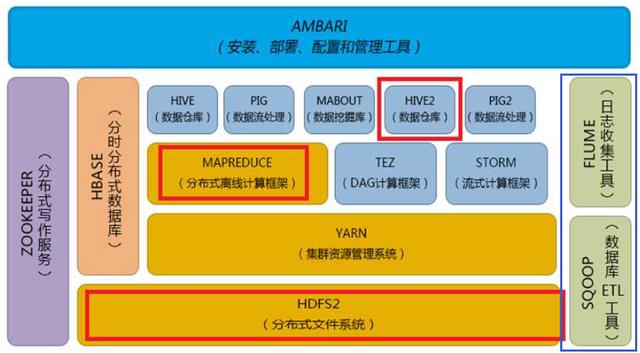
如果从Hadoop提供的标准技术架构和开源工具集,对于数据采集和集成部分重点就是两个工具,一个是Sqoop,一个是Flume。
Sqoop主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并达到各种数据接受方(可定制)的能力。
对于两者的区别简单说明如下:
- Sqoop只支持结构化数据和HDFS之间的数据集成,Flume支持文件和日志
- Sqoop基于Mapreduce的批处理机制,Flume基于事件和流处理机制
- Sqoop偏定时处理,Flume偏实时或准实时处理
- 当面对的是批量和大数据的时候,Sqoop性能好于Flume
在采用Sqoop方式进行数据采集和集成的时候,需要考虑的就是增量数据采集。增量数据导入分两种,一是基于递增列的增量数据导入(Append方式)。二是基于时间列的增量数据导入(LastModified方式)。当前这两种方式Sqoop已经支持。
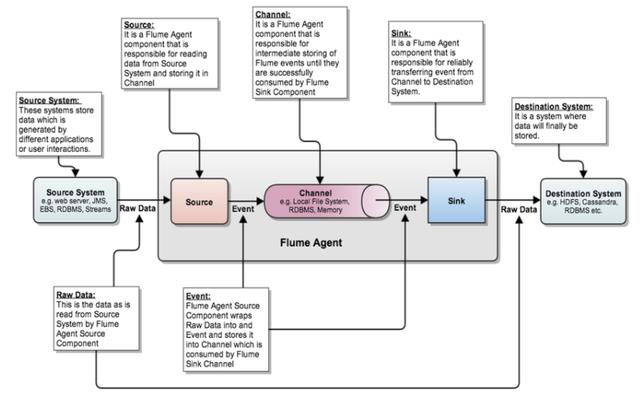
而对于Flume,最早仅用于日志文件的实时采集和处理,而当前的Agent已经能够支持对结构化数据库的适配,也就是说结构化数据库的数据也可以类似流处理的方式采集到Hdfs库。
开源DataX数据采集和集成
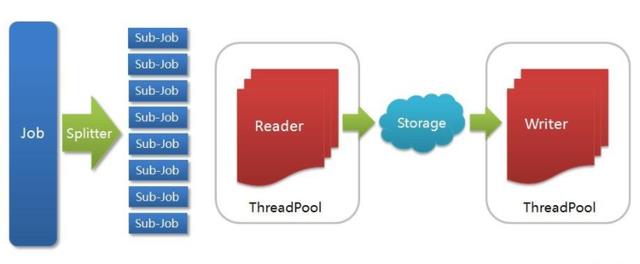
DataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。对于DataX整个架构设计最好的地方就是将Reader和Writer分离,你可以灵活地定义各种读写插件进行扩展。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
我们自己当前研发和使用的DIP大数据集成平台,也是在DataX底层引擎的基础上扩展了数据源配置,数据对象定义和管理,数据调度和任务管理,日志监控等功能。形成一个完善的大数据采集和集成工具平台,如下:
对于DataX可以看到实际和Sqoop大部分功能都相同,但是两者本身架构实现机制还是有差异。Sqoop本身是基于Hadoop的MapReduce机制进行分布式作业,而对于DataX则是自己对Job进行切分,然后并行执行。
对于DataX和Sqoop实际在单节点测试情况来看,两者在性能上的差距并不明显。但是数据源是Oracle,Msyql数据库的时候,DataX的性能略好;而当数据源是Hdfs库的时候,Sqoop性能略好。但是开源的DataX不支撑分布式集群,这个本身也对于大数据量下的架构扩展有影响。单节点的峰值传输能力在15M/S左右。
当前gitbub有对datax定制的管理平台开源,可以参考:
https://github.com/WeiYe-Jing/datax-web
自实现数据采集平台
而对于常规的数据库包括大数据存储之间的采集和集成,在充分考虑性能的情况下,核心思路为:
1. 将源数据库数据进行导出,使用Sql或DB原生的导出命令直接导出为txt文件,字段以分隔符进行分隔。 1.1 可以部署多个代理端,对数据库数据启用多个线程进行导出 1.2 支持基于key值或时间戳的增量数据导出2. 对导出的数据进行压缩后进行传输(特别是在源和目标库不在同一个数据中心时)3. 在目标库端基于数据库原生的load命令对数据进行bulk批量导入。在整个实现里面有两个核心,一个就是可以启用多个代理端和多线程机制并行导出数据库,其次就是导出数据压缩传输,然后在通过load data原生命令进行数据库的bulk批量装载提升性能。
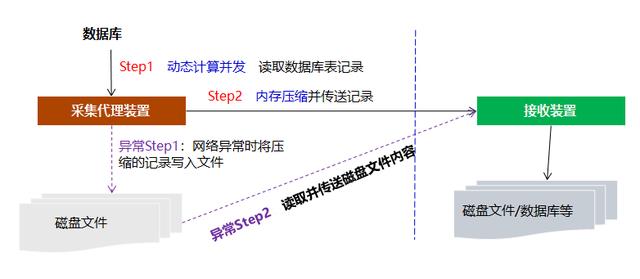
如果基于以上思路我们可以看到数据采集的重点还是在性能上面,不会去实现ETL工具本身复杂的数据映射和转化,数据聚合等操作。核心只是做异构数据库和Hdfs文件存储之间的数据搬移。而我们完全自己研发的DataPipe产品基本参考上述思路实现,其测试性能对于结构化数据库之间采集和集成是Sqoop或DataX的2-3倍左右,而对于hdfs之间的集成则在5-10倍左右的性能提升。
该思路在远程数据传输和集成中,有明显的性能优势。比如内蒙数据中心的批量数据要传输到贵州大数据中心。一个10G的数据在源端导出后并压缩后只有100M左右的大小,整个处理机制则是将压缩数据传输到贵州后再进行解压和入库。
但是整个方案涉及到需要在源端配置Agent代理,因此本身对源端具有一定的侵入性,导致整体应用效果并不太好。
对于这种采集存在的约束就是不要去处理数据变更的问题,仅仅是做数据的全量同步或者是数据库表数据的简单Append处理,否则性能本身会下降很多。如果有大量数据更新需要同步,最好的方式还是首先Truncate掉目标数据库表,然后再进行全量同步。简单验证对于Mysql数据库间100万数据,180M左右数据量的全量同步整体同步时间在14秒左右即全部完成。
虽然这个采集工具现在没有大范围使用,但是却对整体大数据采集和集成实施,功能扩展方面积累了相应的技术经验。
流处理模式
在前面谈Flume日志采集,当时对于日志采集和分析还有比较主流的ELK方案,其中对于日志采集部分重点通过Logstash来实现。
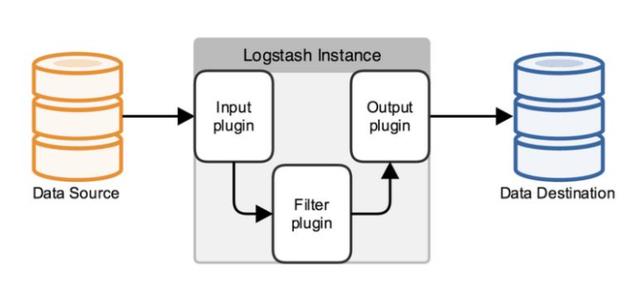
Logstash是一款开源的数据收集引擎,具备实时管道处理能力。简单来说,logstash作为数据源与数据存储分析工具之间的桥梁,结合ElasticSearch以及Kibana,能够极大方便数据的处理与分析。
从上图可以看到Logstash核心就是一个数据源和数据存储间的连接通道,而在ELK方案里面ElasticSearch就是支持全文检索的分布式存储。如果采集的数据量和并发量很大,还可以在ElasticSearch前增加Kafka消息中间件来实现前端输入的削峰处理。
实际上可以看到ELK方案本身和大数据平台的采集和集成关系并不密切,可以看做是针对日志采集分析的一个补充。
如果上面的方式更多的是流式采集和存储的话,还有一个就是流式计算。简单来说就是采集过来的数据不是简单的导入到目标存储中,而是对采集到的数据进行实时的处理和加工,将处理完成后的中间结果存储到目标库中。
比如当前谈得比较多的SparkStream流式计算框架。
举个简单例子,当前我们的ESB总线每天运行3000万次,产生3000万条的实例日志记录,但是我们并不希望将所有数据写入到目标库,而是希望按分钟为单位写入一个统计数据到目标库。传统方式我们是定时进行处理,而采用流式计算框架后可以做到实时或准实时处理。
前面谈采集,可以看到在源和目标之间增加了一个采集集成工具。
即: 源端 -- 采集集成工具 -- 目标端
而流式计算框架后整个过程增加了计算环节如下:
即: 源端 -- 采集集成工具 -- 计算 - 目标端
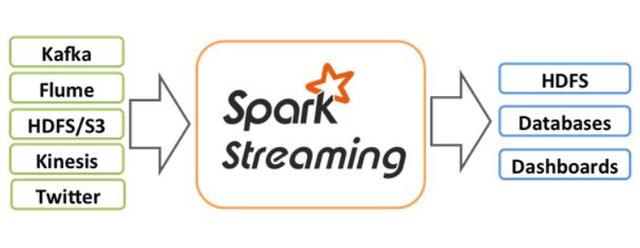
Spark Streaming 是一套优秀的实时计算框架。根据其官方文档介绍,Spark Streaming 有高扩展性、高吞吐量和容错能力强的特点。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。
所以当你的场景不是简单的将原生数据无变化的采集到大数据平台的贴源层,而是需要进行加工处理仅仅写入中间态数据的话,就需要在传统方案的基础上增加类似SparkStream处理环境,或者进行二次采集集成处理。
附大数据的核心技术分类
大数据行业中,主要工作环节包括:
大数据采集
大数据预处理
大数据存储及管理
大数据分析及挖掘
大数据展现和应用(大数据检索、大数据可视化、大数据应用、大数据安全等)。
简单说是这三种:拿数据,算数据,用数据。
一、拿数据
大数据的采集与预处理。
大数据采集一般分为:
大数据智能感知层:主要包括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信号转换、监控、初步处理和管理等。
基础支撑层:提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。
大数据预处理:完成对已接收数据的初步辨析、抽取、清洗等操作。
常见的相关技术:
Flume NG实时日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时,对数据进行简单处理;
Logstash是开源的服务器端数据处理管道,能够同时从多个来源采集数据、转换数据,然后将数据发送到“存储库”中;
Sqoop,用来将关系型数据库和Hadoop中的数据进行相互转移的工具,可以将一个关系型数据库中的数据导入到Hadoop中,也可以将Hadoop中的数据导入到关系型数据库中;
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。

二、算数据
大数据的存储、管理、分析与挖掘。
大数据存储与管理:要用存储器把采集到的数据存储起来,建立相应的数据库,并进行管理和调用。
大数据挖掘:就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
大数据分析:对规模巨大的数据进行采集、存储、管理和分析,这里侧重分析部分。
算数据需要计算平台,数据怎么存(HDFS, S3, HBase, Cassandra),怎么算(Hadoop, Spark)。
这部分包含的较多,其中一些重点:
Hadoop:一种通用的分布式系统基础架构,具有多个组件;Hadoop 的生态系统,主要由HDFS、MapReduce、Hbase、Zookeeper、Oozie、Pig、Hive等核心组件构成;
Spark:专注于在集群中并行处理数据,使用RDD(弹性分布式数据集)处理RAM中的数据。
Storm:对源源导入的数据流进行持续不断的处理,随时得出增量结果。
HBase,是一个分布式的、面向列的开源数据库,可以认为是hdfs的封装,本质是数据存储、NoSQL数据库。
MapReduce:作为Hadoop的查询引擎,用于大规模数据集的并行计算
Hive: 的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。
大数据时代想学习大数据技术,可以考虑下加米谷大数据机构,理论与实践结合小班教学,可以试听,每月预报名中,已培养出许多大数据人才。

三、用数据
大数据的展现和应用。
数据可视化:对接一些BI平台,将分析得到的数据进行可视化,用于指导决策服务。在大数据分析的应用过程中,可视化通过交互式视觉表现的方式来帮助人们探索和理解复杂的数据,可视化与可视分析能够迅速和有效地简化与提炼数据流,帮助用户交互筛选大量的数据,有助于使用者更快更好地从复杂数据中得到新的发现。
Python爬虫:掌握requests库、lxml库(或beautifulsoup4库)的使用基本上可以入门了;
熟练操作数据分析工具(比如Excel、SPSS、SAS等);
掌握数据分析思路,能将数据进行可视化,能够对分析结果进行正确的业务数据解读等。
大数据的应用:大数据的实际应用场景,如金融大数据、教育大数据、餐饮大数据、交通大数据、工业大数据、农业大数据等。
相关参考
数字片库管理系统(数字政府智慧政务大数据体系及大数据治理平台建设技术方案WORD)
...痛点,以云计算、大数据、物联网、区块链、人工智能等技术为支撑,以“统筹规划、集约建设、共享共治”为原则加强XX市大数据顶层设计。1、XX市大数据建设体系规划在本次XX市大数据能力平台项目的建设中,需要规划出一...
...所有者最宝贵资产的性能。将强大的数据集成架构与智能技术相结合,可以让利益相关者更好地理解建筑物的系统和设备协同工作的效果,并为实现组织目标创建明确的路径。专家掌握系统集成和正确的技术堆栈是充分利用物业...
热管型机房空调(达实智能:中标21亿元数据中心机房项目 自主创新研发 提升综合技术能力)
...,建成后将集成大数据、人工智能、物联网、区块链等新技术,构建前海智慧城市的“数字底座”和“信息交互枢纽”。根据项目内容,公司拟采用自主研发的数据中心精准能效控制及管理系统、C3物联网身份识别等核心应用,...
热管型机房空调(达实智能:中标21亿元数据中心机房项目 自主创新研发 提升综合技术能力)
...,建成后将集成大数据、人工智能、物联网、区块链等新技术,构建前海智慧城市的“数字底座”和“信息交互枢纽”。根据项目内容,公司拟采用自主研发的数据中心精准能效控制及管理系统、C3物联网身份识别等核心应用,...
无锡农家乐建设(江苏省无锡市惠山区农业农村局智慧农业大数据平台建设项目)
...代农业发展需求为导向,加快无锡惠山农业与新一代信息技术产业相互融合,以“互联网+大数据”思维统领全局,推动信息技术在农业农村生产、经营、管理、便民服务、各环节的深度应用。项目预算为150万元,主要建设“1+10...
应变仪读数怎么(华和物联WH-IRI-20手持读数仪,操作简单,数据直观)
快速监测技术是基于移动互联网技术、自动化监测技术和传统人工监测技术的基础上的集成、改进、创新和简化技术,具有快速、低成本、高效等特点,是综合性监测技术。手持读数仪作为其中代表产品,专门开发与之配套的云...
数字图像处理4连接8连接题(浅谈数字人文,以数据驱动的人文学科研究方法)
数字人文(DigitalHumanities)是在计算机技术和网络科技普及的基础上,以多媒体表达为辅助,借助各项新兴技术支持开展的以人文学科为对象而形成的新型跨学科研究领域。大数据时代数据科学和数据分析技术的相对普及和低门槛...
大数据时代,数据可视化是其中一项非常火热的应用技术,不管是电商购物节还是各类科技新品发布会,数据可视化都扮演着极为重要的角色。相对于纷繁复杂的数字和文字,可视化图表更能清晰简洁地表达信息,使人们一眼就...
搭建一个算法平台(火山引擎DataLeap:3个关键步骤,复制字节跳动一站式数据治理经验)
DataLeap是火山引擎数智平台VeDI旗下的大数据研发治理套件产品,帮助用户快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,降低工作成本和数据维护成本、挖掘数据价值、为企业决策提供数据支撑。本篇...
汽车配件专卖(汽车维修工具十大品牌排行榜 汽修工具什么牌子质量好)
汽车维修工具十大品牌数据由CN10排排榜技术研究部门和CNPP品牌数据研究部门通过资料收集整理,并基于大数据统计及人为根据市场和参数条件变化的分析研究专业测评而得出,是大数据、云计算、数据统计真实客观呈现的结果...