数值变量资料是指(11个常见的分类特征的编码技术)
Posted
篇首语:世事洞明皆学问,人情练达即文章。本文由小常识网(cha138.com)小编为大家整理,主要介绍了数值变量资料是指(11个常见的分类特征的编码技术)相关的知识,希望对你有一定的参考价值。
数值变量资料是指(11个常见的分类特征的编码技术)

来源:Deephub Imba本文约2500字,建议阅读5分钟本文总结了常见的11个分类变量编码方法。机器学习算法只接受数值输入,所以如果我们遇到分类特征的时候都会对分类特征进行编码,本文总结了常见的11个分类变量编码方法。

1、ONE HOT ENCODING
最流行且常用的编码方法是One Hot Enoding。一个具有n个观测值和d个不同值的单一变量被转换成具有n个观测值的d个二元变量,每个二元变量使用一位(0,1)进行标识。
例如:
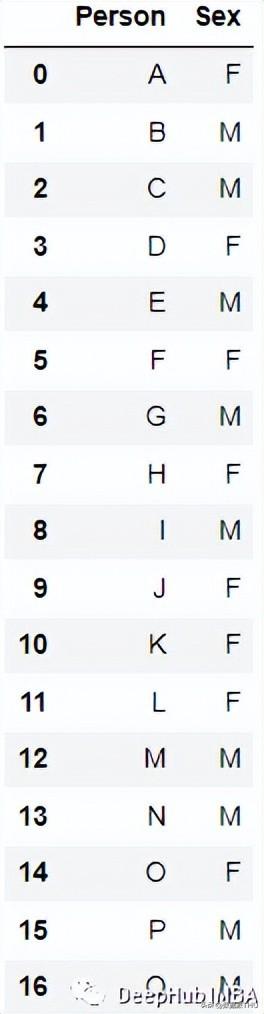
编码后:
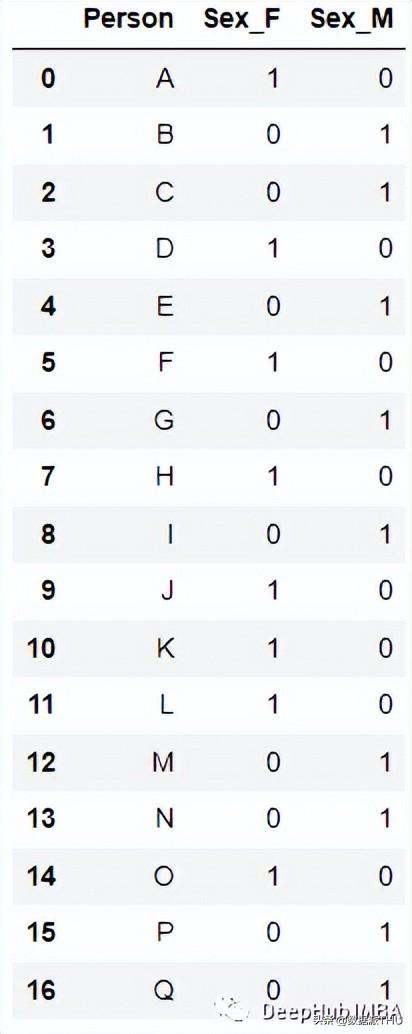
最简单的实现是使用pandas的' get_dummies
new_df=pd.get_dummies(columns=[‘Sex’], data=df)2、Label Encoding
为分类数据变量分配一个唯一标识的整数。这种方法非常简单,但对于表示无序数据的分类变量是可能会产生问题。比如:具有高值的标签可以比具有低值的标签具有更高的优先级。
例如上面的数据,我们编码后得到了下面的结果:
sklearn的LabelEncoder 可以直接进行转换:
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])3、Label Binarizer
LabelBinarizer 是一个用来从多类别列表创建标签矩阵的工具类,它将把一个列表转换成一个列数与输入集合中惟一值的列数完全相同的矩阵。
例如这个数据:
转化后结果为:
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])4、Leave one out Encoding
Leave One Out 编码时,目标分类特征变量对具有相同值的所有记录会被平均以确定目标变量的平均值。在训练数据集和测试数据集之间,编码算法略有不同。因为考虑到分类的特征记录被排除在训练数据集外,因此被称为“Leave One Out”。
对特定类别变量的特定值的编码如下。
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)例如下面的数据:
编码后:
为了演示这个编码过程,我们创建数据集:
import pandas as pd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])然后进行编码:
import category_encoders as ce tenc=ce.TargetEncoder() df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’]) df_dep=df_dep.rename(‘Dept’:’Value’, axis=1) df_new = df.join(df_dep)这样就得到了上面的结果。
5、Hashing
当使用哈希函数时,字符串将被转换为一个惟一的哈希值。因为它使用的内存很少可以处理更多的分类数据。对于管理机器学习中的稀疏高维特征,特征哈希是一种有效的方法。它适用于在线学习场景,具有快速、简单、高效、快速的特点。
例如下面的数据:
编码后:
代码如下:
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)6、Weight of Evidence Encoding
(WoE) 开发的主要目标是创建一个预测模型,用于评估信贷和金融行业的贷款违约风险。证据支持或驳斥理论的程度取决于其证据权重或 WOE。
如果P(Goods) / P(Bads) = 1,则WoE为0。如果这个组的结果是随机的,那么P(Bads) > P(Goods),比值比为1,证据的权重(WoE)为0。如果一组中P(Goods) > P(bad),则WoE大于0。
因为Logit转换只是概率的对数,或ln(P(Goods)/P(bad)),所以WoE非常适合于逻辑回归。当在逻辑回归中使用wo编码的预测因子时,预测因子被处理成与编码到相同的尺度,这样可以直接比较线性逻辑回归方程中的变量。
例如下面的数据:
会被编码为:
代码如下:
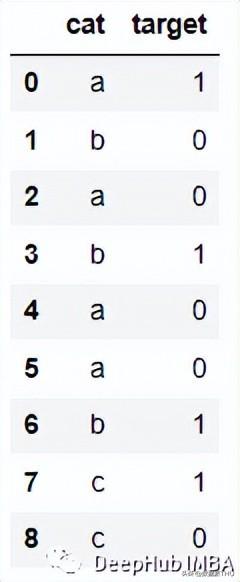
from category_encoders import WOEEncoder df = pd.DataFrame(‘cat’: [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]) woe = WOEEncoder(cols=[‘cat’], random_state=42) X = df[‘cat’] y = df.target encoded_df = woe.fit_transform(X, y)7、Helmert Encoding
Helmert Encoding将一个级别的因变量的平均值与该编码中所有先前水平的因变量的平均值进行比较。
反向 Helmert 编码是类别编码器中变体的另一个名称。它将因变量的特定水平平均值与其所有先前水平的水平的平均值进行比较。
会被编码为:
代码如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf8、Cat Boost Encoding
是CatBoost编码器试图解决的是目标泄漏问题,除了目标编码外,还使用了一个排序概念。它的工作原理与时间序列数据验证类似。当前特征的目标概率仅从它之前的行(观测值)计算,这意味着目标统计值依赖于观测历史。
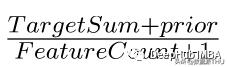
TargetCount:某个类别特性的目标值的总和(到当前为止)。
Prior:它的值是恒定的,用(数据集中的观察总数(即行))/(整个数据集中的目标值之和)表示。
featucalculate:到目前为止已经看到的、具有与此相同值的分类特征的总数。
编码后的结果如下:
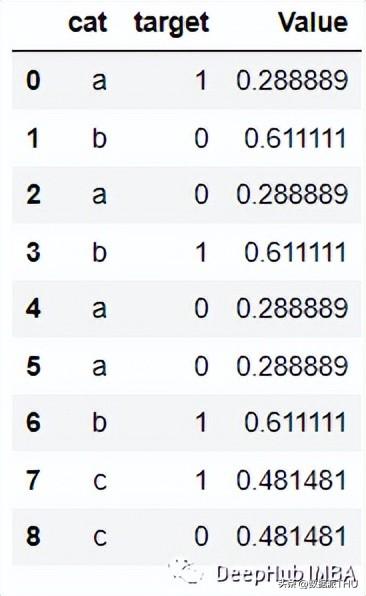
代码:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)9、James Stein Encoding
James-Stein 为特征值提供以下加权平均值:
- 观察到的特征值的平均目标值。
- 平均期望值(与特征值无关)。
James-Stein 编码器将平均值缩小到全局的平均值。该编码器是基于目标的。但是James-Stein 估计器有缺点:它只支持正态分布。
它只能在给定正态分布的情况下定义(实时情况并非如此)。为了防止这种情况,我们可以使用 beta 分布或使用对数-比值比转换二元目标,就像在 WOE 编码器中所做的那样(默认使用它,因为它很简单)。
10、M Estimator Encoding:
Target Encoder的一个更直接的变体是M Estimator Encoding。它只包含一个超参数m,它代表正则化幂。m值越大收缩越强。建议m的取值范围为1 ~ 100。
11、 Sum Encoder
Sum Encoder将类别列的特定级别的因变量(目标)的平均值与目标的总体平均值进行比较。在线性回归(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。两种模型对LR系数的解释是不同的,Sum Encoder模型的截距代表了总体平均值(在所有条件下),而系数很容易被理解为主要效应。在OHE模型中,截距代表基线条件的平均值,系数代表简单效应(一个特定条件与基线之间的差)。
最后,在编码中我们用到了一个非常好用的Python包 “category-encoders”它还提供了其他的编码方法,如果你对他感兴趣,请查看它的官方文档:
http://contrib.scikit-learn.org/category_encoders/
相关参考