摄像机反求是什么意思(如何在虚拟世界里灵活运用你的双手?手势交互方案、算法和场景全解析)
Posted
篇首语:丈夫志四海,万里犹比邻。本文由小常识网(cha138.com)小编为大家整理,主要介绍了摄像机反求是什么意思(如何在虚拟世界里灵活运用你的双手?手势交互方案、算法和场景全解析)相关的知识,希望对你有一定的参考价值。
摄像机反求是什么意思(如何在虚拟世界里灵活运用你的双手?手势交互方案、算法和场景全解析)
早在语言出现之前,人类就习惯使用肢体和手势,这种近乎本能的沟通方式,来互相交流。
在机器被发明之后,手势因具备键盘、鼠标、触屏等交互方式所无法替代的天然优势,仍然有诸多应用场景。
在电影《钢铁侠》里面,主角一挥手,凭空推拉拖拽操控虚拟物体,简直不要太炫酷了。

做到像电影中那样高精度、稳定性好的手势识别,需要硬件和算法的加持,两者缺一不可。
手势识别都有哪些常见的硬件方案?工程师是如何用 AI 算法来优化识别效果的?常见的手势识别应用场景都有哪些?接下来,就让 Rokid R-Lab 算法工程师张兆辉为我们娓娓道来。
手势识别的三大硬件方案
手势识别的原理并不复杂,它通过硬件捕获自然信号,就像相机捕获图片信息那样,然后通过软件算法计算得到手的位置、姿态、手势等,处理成计算机可以理解的信息。
目前手势识别主要有以下 3 种硬件方案:
1、摄像头方案
常见的又分彩色摄像头方案和深度摄像头方案。
1.1 彩色摄像头方案
彩色摄像头方案只需要一个普通摄像头,捕捉拍摄一张彩色图片,通过 AI 算法得到图片中手的位置、姿态、手势等信息。优势是设备成本低、数据容易获取。
目前这种基于单目 RGB 的手势识别在学术界和工业界研究的比较多,商用的方案商有英梅吉、ManoMotion、虹软等。
还有一些人工智能开放平台同样提供这种方案。比如腾讯 AI 开放平台提供静态手势识别和手部关键点,百度 AI 开放平台和 Face++ 提供静态手势检测。以及一些开源项目比如 openpose 和 Google Mediapipe 等。

openpose的手势关键点检测
相比深度摄像头方案,彩色摄像头方案缺乏深度信息,受光照影响非常大,夜间无法使用,稳定性和精度都没有深度相机方案好。
1.2 深度摄像头方案
这个方案是通过深度摄像头来获取带有深度信息的图片。优势是更容易获取手部的 3D 信息,相对应的通过 AI 算法得到的手部 3D 关键点也更加准确和稳定。但缺点是需要额外的设备、硬件成本比较高。
深度相机又分三大类:ToF、结构光和双目成像。
其中,ToF 和结构光得到的深度图比较准,但成本比较高,多用于手势的科研领域,商用的比较少,比如微软 HoloLens、极鱼科技 ThisVR。
双目成像因为视场角大,帧率高,很适合用来做手势识别,唯一缺点就是因为成像原理的限制,使得整个双目相机模组的体积对比 ToF 和结构光来说大很多。
采用双目成像的公司以目前最大的手势识别公司 Leap Motion 为代表,该公司使用的是主动双目成像方案,除了双目摄像头外还有三个补光单元,可捕获双手 26DoF、静态手势、动态手势等。此外,Leap Motion 还提供了非常完整的 SDK,对各个平台支持都不错(除手机平台)。

Leap Motion的演示
国内也有在做双目手势的公司,比如 uSens Fingo 是基于主动双目的视觉方案, 提供双手 26DoF、静态手势、动态手势识别等功能。相比于 Leap Motion,uSens 更专注于对手机以及其他低功耗嵌入式设备的支持。此外还有微动 Vidoo Primary 也有基于双目的手势解决方案。
2、毫米波雷达
毫米波雷达方案的代表有谷歌推出的一款特殊设计的雷达传感器—— Project Soli ,它可以追踪亚毫米精准度的高速运动,但目前尚处在实验室阶段。

从其公布的演示来看,目前可以识别个别指定的手势,并在小范围内识别微小精确的手势操作,很适合发挥人类精准的小肌肉运动技能(fine motor skills)。但缺点是有效范围太小,无法得到手的所有自由度。

Project Soli的演示
3、数据手套
数据手套是指在手上带一个内置传感器的特制手套,通过传感器检测手指的屈伸角度或位置,再根据 Inverse kinematics(逆运动学)来计算出手的位置。
一般用到的传感器有弯曲传感器、角度传感器、磁力传感器等。
弯曲传感器和角度传感器类似都是可检测手指的弯曲程度,我们以 DEXMO 力反馈手套为例,该手套使用旋转传感器捕捉 11 个自由度的手部运动,包括每根手指的伸展和弯曲,以及大拇指一个额外的旋转自由度。

此方案对手的局部动作检测很准,而且不受视觉方案中视野范围的限制。但缺点是手上必须戴手套不方便,且只能检测局部的手指动作,不能定位手部整体的位置角度。若想要检测手的位置角度, DEXMO 需配合其他 6 自由度追踪器使用。
当然 DEXMO 的最大卖点其实不是手势识别,而是逼真的触觉反馈(haptics)+手势识别。手势识别+触觉反馈的方案肯定会是以后人机交互的重要一环。最近收购 Leap Motion 的 UltraHaptics 就是一家做触觉反馈的公司。
还有一种用磁力传感器的——trakSTAR 电磁式空间位置追踪系统。通过在手上贴的磁力传感器的磁场变化,来确定传感器的位置角度,再根据反运动学确定手的具体位置。

trakSTAR使用示意图
此方案需在手部贴 6 个磁力传感器(5个指尖+1个手背),并在面前放一个磁力发射器。磁力发射器会在一定范围内形成一个特殊的电磁场,然后根据传感器在电磁场中不同位置角度检测到的电磁场强度的不同,来推断出指尖及手掌的位置角度。再通过反运动学,确定所有手部关节点的位置。
此方案的缺点是有效使用范围太小,价格太贵,适用场景太少。优点是精度很高,稳定性很好,并且可获得手部所有自由度。
目前此方案还只有纯科研在用,最近几个学术界公开的手势数据集 FHAB、 BigHand 都是用此设备采集的。

FHAB 数据集中的示意图
手势识别的两类算法模型
通过以上科普,相信大家对手势识别的硬件方案有了初步的了解。但要想做好手势交互,仅硬件方案是不够的,还需要专业算法的支持。
当我们通过摄像头得到深度图后,下一步就是把深度图输入给算法,算法可以输出我们手部所有关键点的 3D 位置。
手部关键点也可以理解为手部骨架的关节点,通常用 21 个 3D 关键点来描述。每个 3D 关键点有 3 个自由度,那么输出维度就是 21*3。所以我们常常用一个 21*3 维的矢量来描述,如下图:
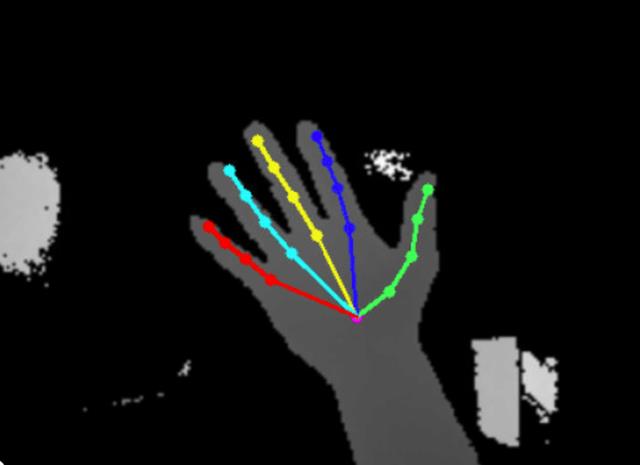
可视化后的21个手部3D关键点
目前学术界已经提出各种算法用于解决“基于深度的手势姿态估计问题“,这些算法大体可以分成模型驱动(model-driven)和数据驱动(data-driven)两种方式。
1、模型驱动类算法
此类算法通常是预先用手部 pose(pose 指位姿参数或节点位置,后文将统称为 pose)生成一系列手的几何模型,并建立一个搜索空间(所有可能的手势几何模型的集合),然后在搜索空间内找到与输入深度图最匹配的模型。
此时,模型对应的参数就是所求的 pose。此类算法属于生成式方法(Generative Approaches),我们以下图中的论文为例:

模型驱动类算法通常需要设计一种方式把 pose 转换成对应的几何模型。
此论文用了 linear blend skinning(一种骨骼蒙皮动画算法):意思就是给骨架蒙上一层皮肤,并让皮肤跟随骨骼运动一起变化,多用于动画领域。
先把 pose 转换成对应的 mesh(下图左侧),在进一步转换成光滑曲面模型(下图右侧)。我们可以理解为 pose 是自变量,几何模型可由 pose 算出,且几何模型与 pose 一一对应。
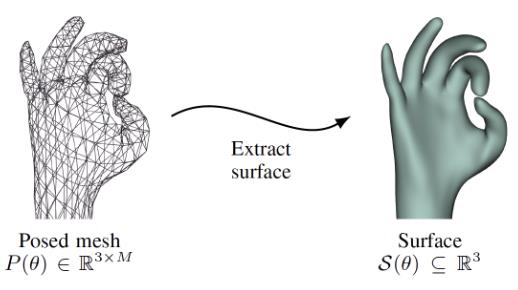
手部几何模型
输入的手部深度图可转化为点云, 此点云就相当于在真实的手表面上采集到的一些 3D 点,如下图中的红点和蓝点:
这样就可以定义损失函数为点云中的点到模型表面的距离(上图中的红线),以此描述深度图和pose的相似度。损失函数的输入是深度图和 pose,输出是差异度。损失函数的输出值越小,说明输入的深度图和pose越相似。
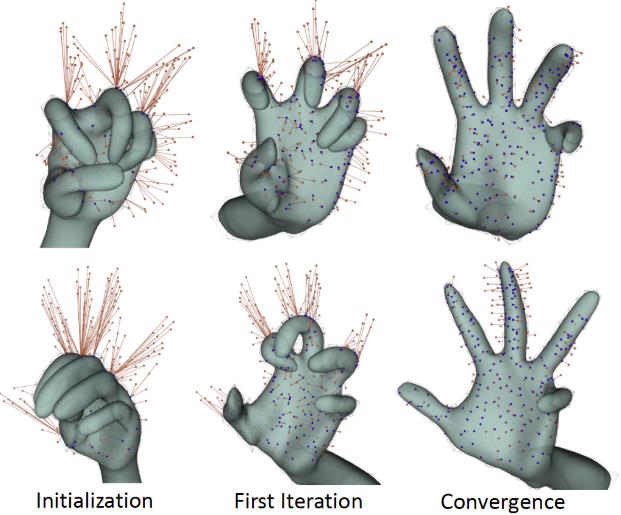
因此,只要在搜索空间中找到令损失函数最小的 pose 即为所求的pose。但因搜索空间不能写成解析形式,没法一次性求出损失函数的最小值,通常只能用数值计算方法,如PSO,ICP等,不断迭代计算得到最优解。
上图从左到右展示了迭代初期到迭代结束时的 pose,这种迭代的数值解法通常对初始化要求较高,若初始化的不好,则需要很长时间才能迭代收敛,还有可能无法收敛到全局最小值(因为损失函数是非凸函数),所以算法实现时,通常利用上一帧的pose来初始化当前帧的计算。
这种模型驱动类方法需要手工设计几何模型和损失函数。简单的几何模型计算量小,复杂的几何模型准确度高。通常设计模型时需要在准确度和性能之间做权衡。
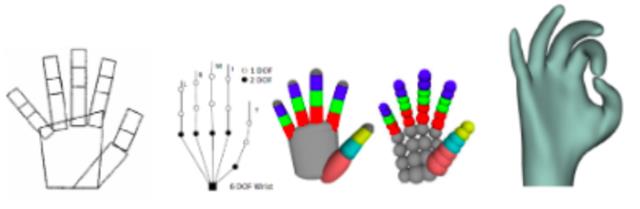
不同的手部几何模型
模型驱动类的算法优势是不需要任何训练数据,只要设计的好,写完就可以直接用。 缺点是需要手工设计模型,计算量较大,容易误差累计导致漂移,对初始化要求高,通常只能用在手势追踪领域。
2、数据驱动类算法
此类算法是指利用收集数据中训练样本与其对应的标签关系,让机器学习一个从样本到标签的映射。 此类算法属于判别式方法(Discriminative Approaches)。
这样的机器学习算法有很多,可以是早期使用的随机森林,SVM 或是最近研究的火热的神经网络等。此类方法的优点是不需要设计复杂的模型,缺点是需要大数据。但现在大数据时代数据量已经不是问题,这种数据驱动的方式已经成为目前的主流研究方向。
早期学术界研究手势关键点回归的经典方法有 Cascade regression, Latent Regression Forest 等。近些年研究主要集中在各类神经网络如:DeepPrior 系列、REN、pose guided、3D-CNN、Multi-View CNNs、HandPointNet、Feedback Loop 等。
由于此处讨论的用于手势的神经网络与普通的图的神经网络并无本质差异,而神经网络的科普文章已经很多,这里就不做科普了,我们仅挑几个有代表性的网络结构介绍一下:
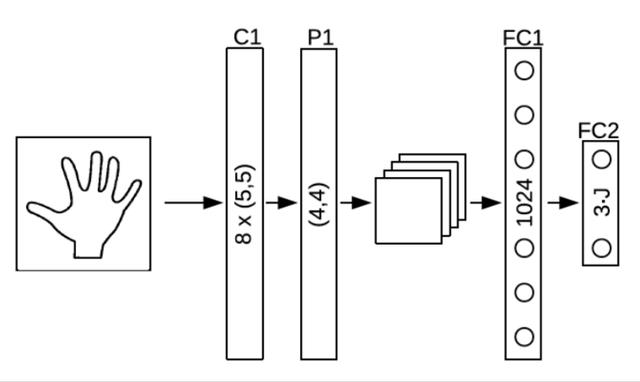
DeepPrior:网络结构大体如下图,通过初始网络得到粗略的 pose,再用 refine 网络不断优化, 并且在最后的全连接层前加了一个低维嵌入,迫使网络学习把特征空间压缩到更低维度。 此网络后续有更优化的版本 DeepPrior++。

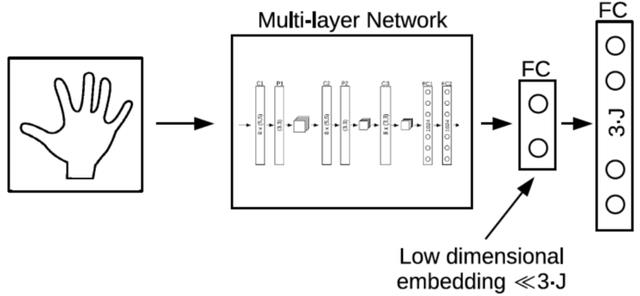
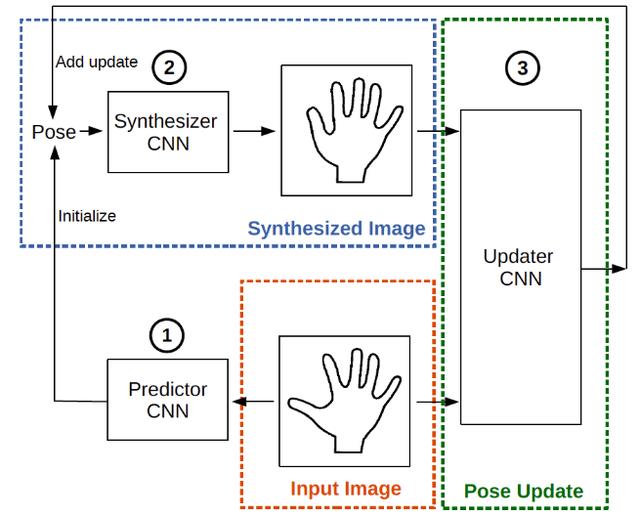
Feedback Loop:网络结构如下图,此网络在预测 pose 之后,反过来用 pose 生成深度图,并与输入的深度图一起预测更优的 pose,此 pose 又可用来生成更优的深度图,以此迭代循环优化pose。
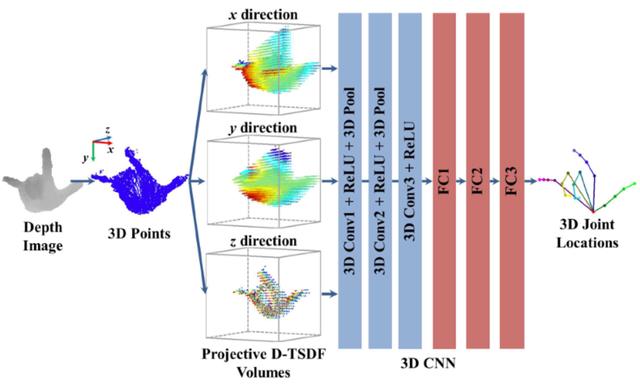
3D CNN:网络结构如下图,此网络把2D深度图上用像素的描述的深度信息,以TSDF的方式转化为体素(3D的像素),并用3D 卷积代替了普通的2D卷积。
此处最大的贡献就是在网络结构上从2D走到了3D,因为传统2D卷积网络是为2D图像设计的,并不一定适合3D信息的提取,而用3D卷积网络则更容易获取3D特征,也就更适用于3D手部关键点回归的问题。
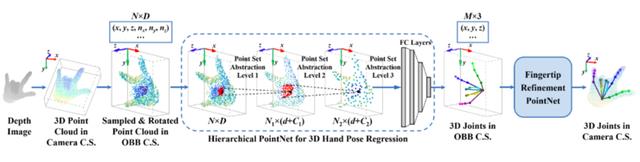
HandPointNet:网络结构如下图,此网络输入时把深度图转成点云,然后用 PointNet 做手部 3D 关键点回归。
HandPointNet的主要贡献是首次把PointNet用在了手势关键点回归上,其中的PointNet是很有代表性的网络。PointNet 首次用 3D 点云来作为网络输入而不是 2D 图片。
PointNet 比上一个介绍的 3DCNN 更进一步探索了在 3D 空间中的神经网络架构,以及如何更有效的提取 3D 特征,PointNet后续有更优化的版本PointNet++。
手势识别的四大应用场景
上述我们介绍了常见的手势识别硬件方案与算法模型,那么手势识别真正落地的应用场景都有哪些呢?
很多人或许认为手势交互还只是停留在科幻电影的概念而已,接下来,我们以产品应用为例,来介绍一些已经商业落地或潜在的落地场景。
1、VR手势
以 Leap Motion 为代表的很多公司都在做 VR+ 手势。 VR 强调沉浸感,而手势交互可以极大的提升 VR 使用中的沉浸感。所以 VR+ 手势这个落地方向很靠谱,等 VR 得到普及后,定会改变人类的娱乐方式。
此类代表产品:LeapMotion、uSens、极鱼科技等。

2、AR手势
以 HoloLens 为代表的很多公司都在做 AR 眼镜。AR 眼镜可能会脱离实体的触屏和鼠标键盘这些输入工具,取而代之的输入是图像和语音等。此时手势交互便必不可少,不过 AR 还处在比 VR 市场更早期的阶段,需继续积累技术,等待市场成熟。
此类代表产品有:HoloLens、Magic Leap、Rokid Glass、Nreal、Project North Star、亮风台等。

Leap Motion Project North Star 的演示片段
3、桌面手势
以 Sony Xperia Touch 为代表的投影仪+手势识别,将屏幕投影到任何平面上,再通过手势识别模拟触屏操作。
这里用到的手势识别比较简单,基本只要识别单点多点。但使用中手很容易挡住投影仪显示的屏幕,而且还有显示清晰度的问题。此场景可能更多的是一种探索,落地的可能性较小。

不过可以开个脑洞:如果把这里的平面手势识别改成空中手势识别,平面投影改成全息 3D 投影,那就可以实现文章开头提到《钢铁侠》里的全息控制台了。
空中手势识别已经能做到了,但目前还没有真正的全息投影的技术,只有一些伪全息投影。如反射式和风扇式的伪全息投影。
反射式伪全息投影只是把物体的影像反射到反射面板(塑料板)后成一个虚像。因板子透明,所以看起来似乎是在空中直接成像。风扇式伪全息投影是利用人眼的视觉暂留现象,让画面看起来像是直接在空中成像。

反射式伪全息投影

风扇式伪全息投影
这些伪全息投影的最大问题就是没法用手和虚拟影像交互。想要实现《钢铁侠》里面的全息工作台,最有可能的方式是在 AR 眼镜里面实现,只要把计算得到的手势位姿和显示设备联合标定对齐,就可以实现手和虚拟影像的交互了。
此类代表产品有:Xperia Touch、光影魔屏等。
4、车载手势
车载手势指的是在开车时用手势交互控制中控台的一些选项按键等。相比于传统方式,手势的优势是不用每次都去按按钮或戳屏幕,更智能方便。
在使用触屏时,司机需要看着屏幕才知道按钮在哪,看屏幕这一动作,有极大的安全隐患。 而手势可以配合语音反馈直接操作,不需要盯着屏幕。
车载手势可以一定程度提高驾驶安全性,但它也有一些缺点,在空中做手势容易手累, 再加上手势识别的准确性和延迟问题,远不如直接用手过去转转按钮、点点屏幕来的方便。所以目前业内基本都采用的都是传统方式+手势操作辅助的方式。
此类代表产品有:宝马7系、拜腾汽车、君马SEEK 5等。

结语
AI 时代,语音识别和手势识别等交互方式的加入,让我们与机器有了更多互动的可能。语音交互在人工智能时代已经有了先发优势,正在被逐渐落地并且有望大规模应用。而从手势识别的落地场景来看,这种交互方式还处在行业早期阶段。
但可以预见的是,手势交互是未来人机交互必不可少的一部分,Rokid 一直致力于 AI 人机交互的研究与探索,代表产品有智能音箱以及 AR 眼镜,期望能在 AI 时代为用户带来自然友好的交互体验。
在你的想象中,还有哪些场景能用到手势交互呢?欢迎大家留言讨论。雷锋网
作者介绍:张兆辉,浙江大学竺可桢学院求是科学(物理)本科毕业,主要研究方向包括手势识别,姿态估计,立体视觉,深度学习等,现就职于 Rokid R-Lab 图像算法工程师,负责手势算法研发等相关工作。
相关参考
怎么连接vr游戏手柄(手上戴个「圈」就能玩 VR,这是什么新玩意?)
...握着厚重的控制器,手臂并不轻松地在空气中张牙舞爪。虚拟游戏中,他的手紧握手柄,变成了哆啦A梦一般的圆球,灵活的手指在磅礴奇幻的新世界却毫无用武之处。不过很快,我们就不用握手柄了。虚拟世界中的手,也将恢...
摄像头变焦什么意思(华为“多摄像头变焦方法、装置及设备”专利公布)
日前,华为技术有限公司申请的“多摄像头变焦方法、装置及设备”专利公布。专利查询截图专利摘要:本发明实施例公开了一种多摄像头变焦方法及电子设备,该方法在多个摄像头切换的过程中,通过依次获取图像,得到拍摄...
手皲裂是什么原因导致的(一到冬天,双手就粗糙干裂?简单3招让手白皙滑嫩又好看)
...样的人打交道,举手投足间,人们都会有意无意的注意到你的手,并且给你的手打分,甚至通过手来判断你的为人和修养,因为脸上的表情可以假装,但是手不能,它会将你内心真实的想法显露出来。很多女人在冬天都会出现双...
手上皮肤很嫩说明什么(一到冬天,双手就粗糙干裂?简单3招让手白皙滑嫩又好看)
...样的人打交道,举手投足间,人们都会有意无意的注意到你的手,并且给你的手打分,甚至通过手来判断你的为人和修养,因为脸上的表情可以假装,但是手不能,它会将你内心真实的想法显露出来。很多女人在冬天都会出现双...
...,面对复杂的城市空间,主角轻轻一点,面前会出现一个虚拟的画面,能真实再现该空间的所有动态信息,主角就可以“有如神助”轻车熟路地进入该空间,完成不可能的任务。这种在虚拟世界再现真实世界的技术被称为“数字...
梦幻西游手游装备特技(梦幻西游:体力灵活运用的方法,不是合宝石,也不是分解天眼)
一个角色身上分为体力以及活力,活力可以制作烹饪、炼药以及制作临时符等,而体力的作用范围要比活力广,而且价值也比活力高。目前常见的体力处理方法就是直接去书店打工换钱,每40点体力就可以换取3000两游戏币。但稍...
摄影构图的五种基本规律(掌握这7个技巧,灵活运用线条,让你的摄影构图更完美)
日常生活中,线条随处可见,作为摄影师,我们在拍照时,要善于发现这些线条,然后将它们运用在构图中,可以给照片增加感情上的内容,还可以引导观众的视线,使观众的注意力集中在画面上。当你能熟练运用这些线条,就...
...和食指指尖的动作,常常来暗指金钱或是表达索取金钱的意思。两只手的手指尖对在一起形成塔尖状,会让人看起来胸有成竹,自信十足。这个手势经常出现在上下级之间的
...手液来给大家,以致让ta除菌效果出众之外,并且还能让你的双手时刻保持洁净,让你远离细菌的侵扰。精选优质植物提取成分,不含荧光剂、酒精等有害物质,温和不伤手,泡沫丰富细腻,清洁力度强,能深入肌肤底层,有效...
怎么判断烟感是不是摄像头(酒店、试衣间暗藏针孔摄像头?这反偷拍探测报警仪,让你睡得安稳)
...直播娱乐!最近一条关于一对情侣在入住酒店时,被针孔摄像头偷拍的新闻话题,几乎占据了所有主流媒体的新闻榜首,让人看后不由的细思极恐。《人民日报》和《中国青年报》都对其进行了报道。在围脖里这一新闻话题,更...