手机中的N卩U是什么(通用NPU与针对自动驾驶系统NPU的差异点和挑战)
Posted
篇首语:学如逆水行舟,不进则退。本文由小常识网(cha138.com)小编为大家整理,主要介绍了手机中的N卩U是什么(通用NPU与针对自动驾驶系统NPU的差异点和挑战)相关的知识,希望对你有一定的参考价值。
手机中的N卩U是什么(通用NPU与针对自动驾驶系统NPU的差异点和挑战)
作者:Shawn O,英国复睿微电子剑桥研发中心GRUK NPU架构师,常驻英国剑桥
未来几十年,自动驾驶技术将重塑整个社会。当车内的乘客可以将手和注意力从驾驶中释放出来,这将颠覆现在大部分的商业模式,例如购物、视频、游戏等。同时,交通运输的效率也将大幅提高, 人类社会将会得到极大的提升。
但现在对于自动驾驶和智能汽车行业来说,还处于非常早期的阶段,只有L2和L3的解决方案部署在高端汽车上,而L4以上目前还没有成熟稳定的解决方案。特斯拉、华为、小鹏、蔚来等厂商推出了L3/L4自动驾驶解决方案,而大众、福特、捷豹、路虎等传统汽车厂商也在部分产品中推出了不低于L2的自动驾驶解决方案。
然而,为了实现这个梦想,我们需要无限的计算能力、无限的存储空间、超强的可靠性,当然,这些不仅只是针对豪华汽车,而是普惠车型上也能实现让每个人都能负担得起的成本。这与过去十年智能手机市场所发生的情况如出一辙。
相信中国在未来十年可以成为自动驾驶的领先营销之一,因为中国有许多新的电动汽车巨头,如蔚来、小鹏、理想、比亚迪和吉利汽车,另外加上政府正在积极鼓励电动汽车取代传统的汽油动力汽车,以实现产业升级。
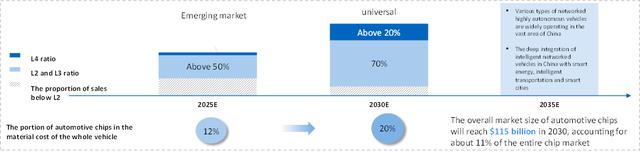
我预计,到2025年之前超过50%的新车销售将提供L2/L3自动驾驶功能,到2030年这一数字将增加到90%。到2030年,汽车芯片整体市场规模将达到1150亿美元,占整个芯片市场的11%。
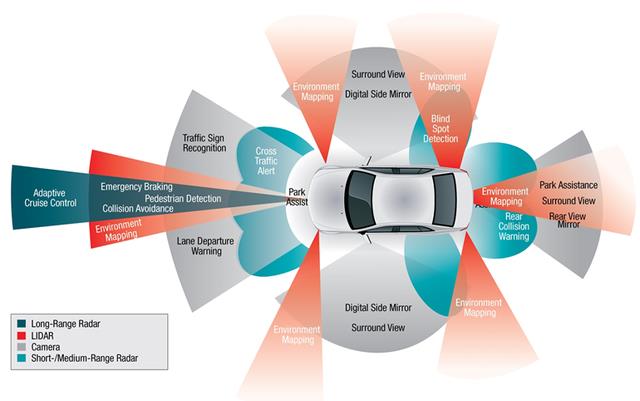
阻碍自动驾驶普及的原因有很多,除了在所有复杂的真实环境中仍然没有足够的来自车队的测试和验证数据外,个人认为计算能力是限制L4以上自动驾驶的主要因素。典型的L4自动驾驶系统会有4-6个雷达,1-6个激光雷达,6-12个摄像头和8-16个超声波。传感器将产生共计3Gbit/s (~1.4TB/h)到40gbit /s (~19 TB/h)之间的数据。
例如,Waymo的自动驾驶汽车有8个摄像头、6个雷达和6个激光雷达。为了处理这些数据,对于L4自动驾驶来说,计算能力要求可能在1000TOPS以上,而L5可能是L4的10倍,达到10000TOPS。不过,目前主流的解决方案也只有100TOPS-250TOPS左右。

然而,用于自动驾驶系统的NPU并不仅仅是计算能力,它可能有其独立于一般NPU的特点。为了设计出具有竞争力的自动驾驶NPU,我们需要同时理解通用NPU和ADAS NPU所面临的挑战。
通用NPU和超大算力芯片组面临的巨大挑战
随着摩尔定律失效,通用NPU和超大算力芯片面临的主要挑战可以从功耗墙、内存墙和利用墙等方向着手分析问题和挑战;
功耗墙:
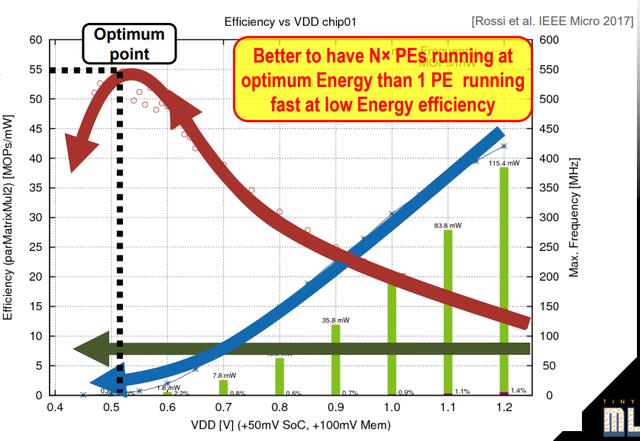
下图展示了微处理器发展的40年趋势。从20世纪70年代到现在,晶体管的密度以指数级的速度增长,频率和单线程性能也同样增长,直到2000年代中期,登纳德微缩失效。因此,峰值的时钟速率稳定在3-4 GHz左右,功耗峰值在几百瓦的范围内。

通常下一代CMOS工艺比上一代的晶体管电容(以及开关功耗)的下降幅度约为S倍(比例因子,例如32nm工艺对比22nm工艺尺寸下降了1.4倍),同时晶体管开关频率可以提高S倍,而相同尺寸的芯片上的晶体管数量增加了S^2。
在登纳德微缩理论有效的情况下,我们可以将阈值缩放为1/S,因为不存在短沟道效应,漏电流没有上升,而单个晶体管的电容值也下降了S倍,因此在芯片最高频率可以提升S倍,而晶体管数量增加S^2,所以即使性能提升了S^3倍,但是功耗却还是保持不变,因此并不会遇到功耗墙的挑战。
但是在登纳德微缩理论受限制的情况下,则阈值电压无法缩放,因为在极小尺寸下产生短沟道效应漏电流会上升到不可接受的水平,而单个晶体管的电容值也下降了S倍,则单个晶体管的开关功耗仅下降为1/S。如果把频率提升S倍,同时晶体管数量也增加了S^2倍的话,在最高频率的功耗会上升到S^2倍。
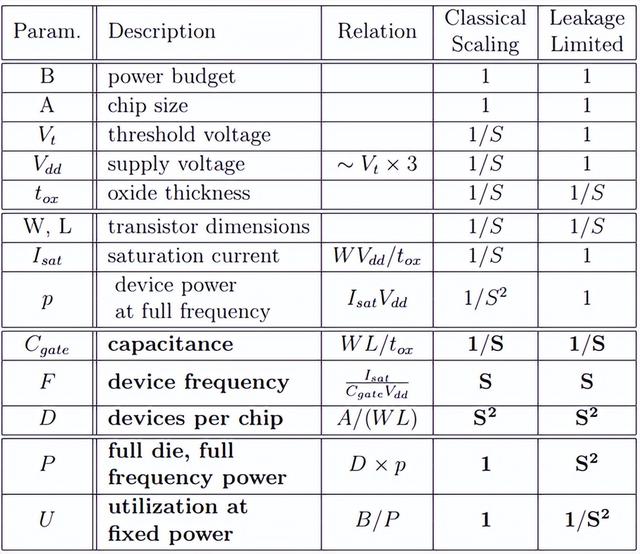
如下图所示,当芯片在工艺上65nm制造时,可以实现在1.8GHz频率下跑4个核。而演进至32nm时,则因子S=2,在相同的面积下可以实现2^2*4=4*4=16个核。假如由于设备散热的限制芯片的功耗需要保持一致,且登纳德微缩理论受限制,则要么保持频率不变为1.8GHz,则有8个核可以同时运行,其余8个核处于挂起状态;或者提升频率2倍为3.6GHz,则只有4个核可以同时运行,其余的12个核处于挂起状态;或者实现16个核同时运行在0.9GHz频率下。图中黑色区域表示处于挂起状态的核,灰色则表示运行在低频状态的核。

单位面积的产生功耗以及每TOPS消耗的功耗等要比单位面积的性能密度更为重要,因为除了对于少数对于尺寸空间极为受限的设备,大多数场景下芯片面积只是意味着成本,但是芯片的成本可以通过增加发货量摊薄。而能效比太差则会导致芯片发热,降低芯片可靠性,甚至使得整个设备失效。因此,NPU的设计主要需要考虑如果将上图黑色和灰色部分的面积有效地使用以提升芯片的能效比。可以考虑如下的几种方向:
1.利用由于先进工艺带来的多余面积实现针对专有任务的加速器或协处理器实现异构架构,使得在特定任务上比通用处理器快得多或节能得多。例如针对深度神经网络当中不同类型的算子可以通过专用的处理模块,例如卷积和全连接,Pooling和激活函数分别可以用不同的处理模块实现最高效率,而非在同一通用处理模块中实现。
2.通过动态电压和频率调节(DVFS)来实现功耗的调节,针对一些规模较大的深度神经网络,且时延和精度要求比较高的应用,则允许芯片暂时在频率翻倍情况下运行一段时间超过名义热预算,依赖热电容缓冲系统温度的升高,而针对规模较小的模型或者时延不敏感的任务,则配置是的芯片在正常低压低频的状态下实现最佳功耗。例如英特尔的turbo boost,海思的GPU Turbo都是采用类似的方案;

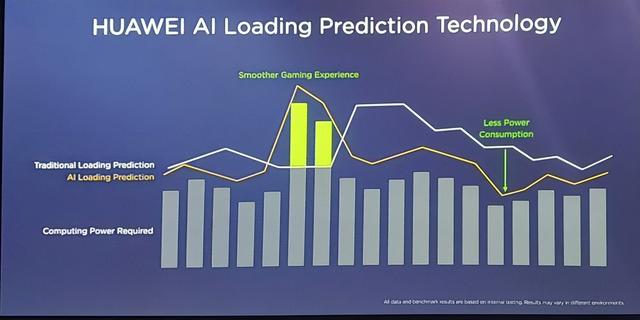
3.用低性能的众核跑在低频和低压上实现的并行计算来代替一个高频高压高性能的大核达到能效比的最大化。
如下图所示,虽然降低频率的同时也会降低处理器的速度,但是功耗效率可以得到提升,这是因为随着频率降低,工作电压也可以降低,从而导致Transistor的开关的动态功耗降低,而静态功耗主要来自漏电流几乎保持不变。
因此,我们可以看到将工作电压降低在阈值附近(NTV)可以实现最佳的能效比,而工作电压低于该值后漏电流会急剧上升,Transistor无法正常工作,阈值电压是由工艺决定的。另一方面随着DNN网络规模越来越大例如resnet,Inception以及VGG等等,同时并行度也越来越高,这样更易于能够充分利用并行计算在实时性满足的情况下提升能效比,这点对于端侧的AI芯片的尤为重要。
4.基于粗粒度可重构阵列(CGRA)的架构试图通过减少处理器内部的实现复杂数据路径的多路复用,大大简化PE的复杂度,减少流水线级数,则更容易实现之前提到的近阈值NTV运算,提升单个PE的能效比。同时根据PE单元的数据位带宽,设计粗粒度大于4 bits的可重构数据通路,这样即可以满足DNN在不同精度(4 bits,8 bits以及16 bits等等)下可配置的需求以实现推理的最高效率。
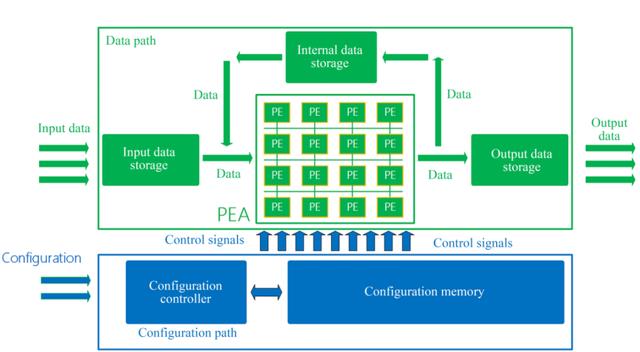
5.将多余的面积用于增加更多Cache或者on-chip SRAM,以减少由于cache miss导致从Off-Chip的数据读取,从而减少功耗的浪费。当然,设计片上Cache和SRAM需要匹配好PE的处理速率和存储带宽,使得三者之间没有相互限制。
内存墙:
微处理器性能的提升速度远远超过DRAM存储速度的提升速度,因此处理器和片外DRAM存储访问之间存在着巨大速率差,如果处理器每条指令需要处理数据都从DRAM访问,那么会大大地降低处理器的性能。

因此需要在处理器和片外DRAM之间增加比DRAM访问速率更快的存储单元例如片内寄存器和cache等等,这就使得内存层次结构变得异常复杂。处理器在内存管理和阮存缺失上也会花费了大量的执行时间,这也会导致功耗的增加和性能的下降。

谷歌研究了在TPU中实现的边缘设备的谷歌神经网络模型(CNN, RCNN, LSTM和Transformer)的瓶颈是什么。有两个关键的观察结果:
1、62.7%的系统能耗是花费在数据移动上
对于CNN模型,48.1%的静态能量和36.5%的动态能量花费在片上缓冲区的参数访问和存储上。在所有模型中,边缘TPU平均将50.3%的总功耗用于片外内存访问(包括DRAM能量和片外互连能量)。
2、数据移动的很大一部分通常来自内存中的简单函数,如乘累加和移位等等。

基础以上的两点观察,针对深度神经网络处理器的设计,要解决内存墙的问题,则需要从以处理器为中心的计算方式转换为以数据为中心的计算方式,即处理器中的计算函数搬移到数据存储的地方而非把数据搬移到处理器中进行计算。主要有如下两种思路:
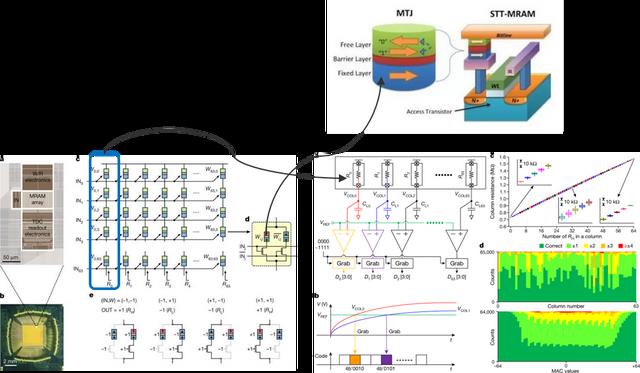
解决方案1:内存计算,将应用卸载到PIM (processing in memory)中,降低能耗,提高性能。例如三星电子在2022年在Nature公开了首例基于MRAM的存算一体处理器,用于神经网络加速。该芯片构建了一个64×64的MRAM阵列,该论文中实现了将VGG类的人脸识别算法中的某一层offload到MRAM存算芯片上运行,从测试数据上看,仅用0.56mW就达到了0.63FPS的人脸识别速率,达到了极高的能效比。
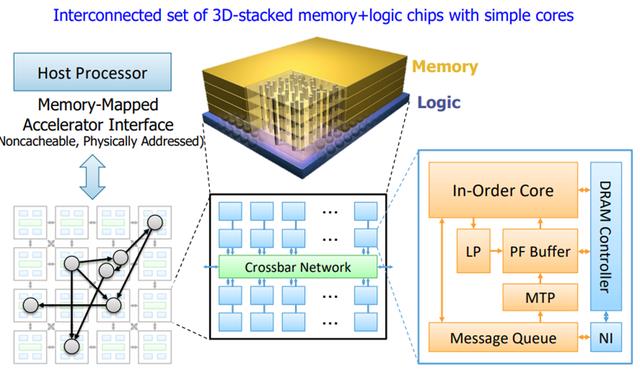
解决方案2:将计算移至内存附近,甚至在内存中计算。如下图所示为一种以数据为中心的近内存计算的设计构架,最终该架构主要的思想为将函数(即计算和临时值)移动到需要更新的数据相近的核当中,而不是将存储在不同的内存分区的数据搬移到运行函数的核当中实现计算,主要通过三点设计实现:
(1)通过在逻辑层放置简单的in-order处理核心,有效地利用3D堆栈内存中的可用内存带宽,并使每个核心只能操作在垂直方向上被分配的内存分区上的数据
(2)在三维堆叠内存中不同的in order核心之间的设计一种有效的通信方法,使每个核心能够对由另一个核心控制的内存分区中的数据发起计算请求。
(3)设计一种基于消息传递的编程接口,类似于现代分布式系统的编程方式,它允许对驻留在每个内存分区中的数据进行远程函数调用。通过以上几点设计:

利用率墙:
芯片的峰值计算能力是一回事,而AI芯片的利用率是另一回事。从下表中我们可以看到,对于不同的DNN型号,DNN加速器的利用率大多在50%以下。尤其像英伟达这类通用GPU的架构,实际利用率仅仅在30%以下。
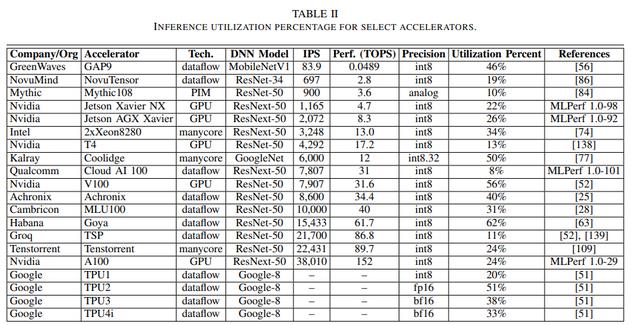
要提高DNN加速器的利用率,有以下几个潜在原因:
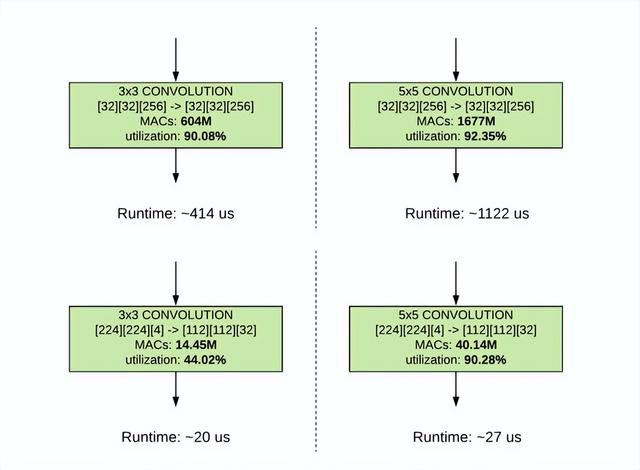
1.针对特定硬件优化优化模型的结构和编程。例如,谷歌发布了EffecentNet - EdgeTPU,这是一个从EffecentNets衍生而来的图像分类模型,但针对谷歌的边缘TPU进行了定制化优化。原生的EffecentNets主要依赖于深度可分离卷积(depthwise sparable convolution),以减少参数的数量和计算量。
但是google研究团队发现在Edge TPU上较浅深度的输入张量(224*224*3)与较大的深度的输出张量(112*112*32)以及较小的卷积核尺寸(2*3)的组合具有较低的利用率(44.02%),而增加卷积核的大小,其中由于利用率的提高,内核大小的增加对运行时的影响较小。
因此在该情况下Edge TPU上一个常规的3x3卷积(右)比一个深度可分离的卷积(左)有更多的计算(乘法和累积(mac)操作),由于2倍的有效硬件利用率,常规的3*3卷积在Edge TPU上执行得更快。

2.反过来从硬件微架构角度,也要考虑如何高效地支持灵活的算子以适应不同DNNs实现高利用率。例如,华为Davinci AI核心实现了一个包含标量单元、矢量单元和立方体单元(Cube)的异构架构,它提供conv 3*3、conv 1*1、Pooling、activation等各种神经网络需要的算子。
例如Cube的大小可定制为4*4*4、16*16*16或32*32*32等,可以支持不同精度如INT4、INT8到FP 16、FP32等等。矢量宽度可定制为32字节、128字节或256字节。立方体的大小和向量的宽度越大,那么计算密度就越高。然而,一些神经网络不能充分利用MAC,因此Cube单元可能会因为利用率而失去它的优势。
3.片外存储带宽,NPU核心计算能力以及片内存储大小的匹配以及合理的data path会影响NPU计算单元的利用率。这和之前提到的内存墙有点类似,一般NPU核心的算力增长要快于DRAM的访问速率,因此需要实现片内内存用作缓存。
一般神经网络的计算是以每一层为单元计算的,例如卷积层,pooling层等等。首先需要将输入以及权重数据从片外DRAM搬运到片内SRAM当中供计算单元PE使用,一旦PE需要处理数据在缓存中未命中,也需要去DRAM中访问,在数据搬运至片内SRAM中之前,PE单元处于饥饿状态,则利用率下降。
因此,需要一次性搬运好网络某一层所需要的所有数据能够快速搬运至SRAM当中,所有的中间结果也都可以再SRAM存储复用,不用写回到片外DRAM中。另外一般神经网络中的以层的输出往往就是下层的输入,因此输出数据也需要存储在SRAM当中复用,避免去片外DRAM读取。
自动驾驶NPU的特点和独特挑战
设计ADS系统中的NPU,不仅需要考虑我在上一章提到的常见挑战。ADS系统有自己的特点,在设计NPU时需要考虑。
ADS系统的任务包括感知、感知、定位、规划、控制、驱动等。每个任务可能包含多个子任务,如感知内部的目标检测、识别和分割。而所有这些任务并不是相互独立的,它们共同的一个最终目标就是确保车辆安全有效地行驶在车内。
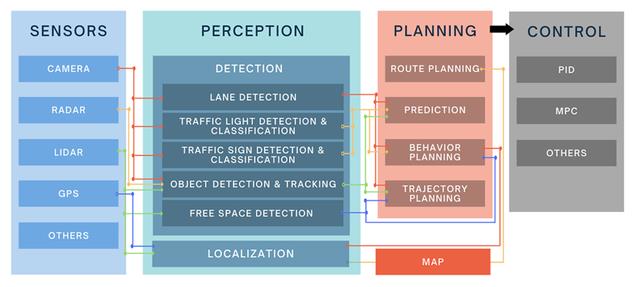
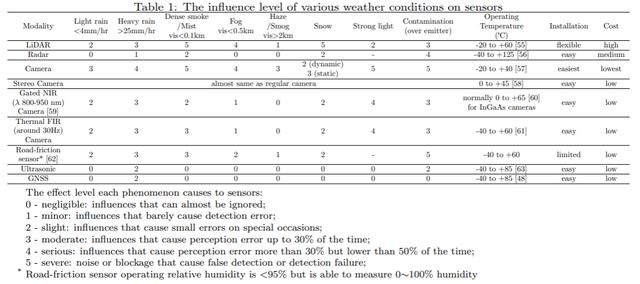
系统输入通常涉及多个传感器的数据,比如多个摄像头的图像,雷达和激光雷达的点云,超声波信号,位置、速度和加速度传感器的数据,以及声音和运动信号。在各种天气条件下,不同传感器的影响差异很大,可以下图中看到,不同传感在在某些恶劣天气下会完全失效。因此,需要多模态传感器融合解决方案来保证不同场景下任务的最佳输入质量,根据外部天气环境动态调整不同数据输入的权重和融合方式。
从硬件的角度来看,ADS SoC通常是异构架构。除了NPU,还有cpu、DSP、GPU等图像信号处理器。

所有的任务和子任务都需要在异构中映射到不同的核上。
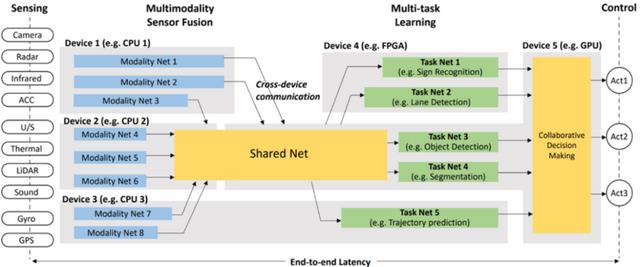
基于以上对于ADS系统的描述,因此在ADS SoC中设计NPU需要考虑以下几点:
首先,在ADS系统中有一组不同的DNNs,如Resnet, FPN, Transformer,它们需要并行或级联运行在NPU中以处理ADS系统中不同任务的多模态数据;这些不同任务的深度神经网络可以进行分层的特征共享/融合。NPU不仅仅针对一个特定的深度神经网络中优化硬件的利用率和功耗效率,更要考虑到每个深度神经网络和任务的运行时间比例和哪些DNNs之间需要层间的特征共享/融合,以获得整体最优的利用率和功耗效率。
因此,我们需要设计一种可重构硬件架构,能够在运行时高效地为不同的dnn和任务配置。并实现硬件感知的神经网络搜索(NAS),不仅可以在一个DNN上搜索特定的任务,还可以进行多通道和多任务架构的搜索。更重要的是,这不是在NAS中分别优化每个单独的任务。对于ADS系统,其目标是优化最终的驱动/控制,而感知、定位等中间任务则协同服务于最终目标,因此需要实现多网络协同优化达到整体最优结果。
其次,ADS系统的决策依赖于多种输入下多个深度神经网络和任务的输出综合全面地做出决策,这些深度神经网络的输入是来自不同传感器的多模态信号,质量会受到外部环境或场景的影响,其输出有效性也会相应地打折扣。因此每单个的神经网络模型推理精度是可以适当调整的。因此,在ADS的DNNs推理中需要可调整的混合多精度,即可以针对同时在运行的不同模型实现不同精度下的推理,甚至同一模型下不同层间的精度也可以不同。
第三,ADS系统强调实时和快速响应。当接收到传感器输入,考虑依赖于这些输入产生的控制输出,那么对传感器数据的处理必须按时完成。因此,我们需要保证网络的实时性-这对安全性和性能都至关重要,特别是在汽车高速行驶的情况下。
这是ADS DNN推断与主流通用ML非常不同的一个重要例子。而任务的DNN推断的延迟不仅取决于NPU核心内部计算能力和数据流的并行性,还取决于通过SoC系统总线对外部存储的访问。因此,我们需要在NPU和SoC层面设计QoS机制,能够提供基本的权限管理并避免关键任务处于饥饿状态。
最后,超级可靠性的要求也使得面向ADS的NPU不同于一般的NPU。ADS SoC芯片整体需要通过AEC Q100车用芯片可靠性标准。
基于以上分析,我们把面向ADS SoC系统的NPU概括为实时可重构的可靠多模态多任务(MMMT) DNN加速器,ADAS NPU面临的挑战来自几个方向,主要包括以下几个关键问题:
1.针对需要支持的自动驾驶系统中所需的不同DNN模型设计layer wised计算模式
a)如何为ADS系统DNN模型设计高效的数据流,以便提高不同层次DNN的输入、权重和输出等数据的可重用性,并减少硬件所需的MAC操作次数?
b)如何设计一种在不同场景(如雨雪等恶劣天气)下,利用混合精度对ADS进行效率和精度量化权衡的方法?通过降低数据的精度,使量化模型在保持与全精度模型(FP32)相似精度(95%)的情况下,可以实现X倍的模型尺寸或X倍的计算成本降低,从而最大限度地减少精度损失,最大限度地提高效率
c)定义ADS系统中用于不同DNN模型的常用基本计算算子。除了基本的CONV 3*3、CONV 1*1和Pooling等等之外,针对ADS系统特诊定义特殊算子,例如跨层共享/融合,精度转换等等;
2.根据计算模式设计一个高效的实时可配置硬件架构:
a)如何设计能够通过MAC和SMID实现基本运算符和预取器的异构PE微体系结构,并高效地支持精度和稀疏度混合计算?
b)设计紧密耦合的存储层次和系统,减少数据移动,提高不同深度神经网络层间的可重用性。
c)设计支持数据流或计算模式的片上网络(network-on-chip, NoC),在ADS系统中高效连接PE和内存,并为任务提供QoS机制。
3.设计多通道多任务的硬件-算法协同设计流程,对每个任务进行整体优化而不是分别独立优化
a)根据我们的NPU硬件架构,为DNN搜索空间构建硬件优化的典型DNN模型结构,并通过硬件感知的NAS将其充分映射到硬件配置空间
b)如何保证仿真结果的可信度?不但要包括该算法的输出延迟、精度均小于5%,还要有功耗的估算,且精度要达到20%,且与实际芯片性能呈线性关系,以便觉得最优的硬件配置方案和神经网络结构优化。
参考:
1.M. B. Taylor, "Is dark silicon useful? Harnessing the four horsemen of the coming dark silicon apocalypse," DAC Design Automation Conference 2012, 2012, pp. 1131-1136.
2.Tu, Fengbin & Yin, Shouyi & Ouyang, Peng & Tang, Shibin & Liu, Leibo & Wei, Shaojun. (2017). Deep Convolutional Neural Network Architecture With Reconfigurable Computation Patterns. IEEE Transactions on Very Large Scale Integration (VLSI) Systems. 25. 2220 - 2233. 10.1109/TVLSI.2017.2688340.
3.M. S. Abdelfattah, Ł. Dudziak, T. Chau, R. Lee, H. Kim and N. D. Lane, "Best of Both Worlds: AutoML Codesign of a CNN and its Hardware Accelerator," 2020 57th ACM/IEEE Design Automation Conference (DAC), 2020, pp. 1-6, doi: 10.1109/DAC18072.2020.9218596.
4.Mutlu, Onur & Ghose, Saugata & Gómez-Luna, Juan & Ausavarungnirun, Rachata. (2020). A Modern Primer on Processing in Memory.
5.Boroumand et al., "Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks," 2021 30th International Conference on Parallel Architectures and Compilation Techniques (PACT), 2021, pp. 159-172, doi: 10.1109/PACT52795.2021.00019.
6.Venieris, Stylianos & Bouganis, Christos & Lane, Nicholas. (2022). Multi-DNN Accelerators for Next-Generation AI Systems. 10.48550/arXiv.2205.09376.
7.E. Wang, J. J. Davis, P. Y. K. Cheung and G. A. Constantinides, "LUTNet: Rethinking Inference in FPGA Soft Logic," 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), 2019, pp. 26-34, doi: 10.1109/FCCM.2019.00014.
8.A. Reuther, P. Michaleas, M. Jones, V. Gadepally, S. Samsi and J. Kepner, "AI Accelerator Survey and Trends," 2021 IEEE High Performance Extreme Computing Conference (HPEC), 2021, pp. 1-9, doi: 10.1109/HPEC49654.2021.9622867.
9.AutoML, E., 2022. EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML. [online] Google AI Blog. Available at: <https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html> [Accessed 16 July 2022].
10.stateof.ai. (2021, October). State of AI Report. https://docs.google.com/presentation/d/1bwJDRC777rAf00Drthi9yT2c9b0MabWO5ZlksfvFzx8/edit#slide=id.gf171287819_0_165
公司介绍:
复睿微电子是世界500强企业复星集团出资设立的先进科技型企业。复睿微电子植根于创新驱动的文化,通过技术创新改变人们的生活、工作、学习和娱乐方式。公司成立于2022年1月,目标成为世界领先的智能出行时代的大算力方案提供商,致力于为汽车电子、人工智能、通用计算等领域提供以高性能芯片为基础的解决方案。
目前主要从事汽车智能座舱、ADS/ADAS芯片研发,以领先的芯片设计能力和人工智能算法,通过底层技术赋能,推动汽车产业的创新发展,提升人们的出行体验。在智能出行的时代,芯片是汽车的大脑。复星智能出行集团已经构建了完善的智能出行生态,复睿微是整个生态的通用大算力和人工智能大算力的基础平台。复睿微以提升客户体验为使命,在后摩尔定律时代持续通过先进封装、先进制程和解决方案提升算力,与合作伙伴共同面对汽车智能化的新时代。
相关参考
数控实训内容怎么写(数控车床上实训中的工艺与编程(三)实例)
4.实例编程锉刀手柄在“GTC2E”数控车床上进行加工的编程如下。N00010M03S600N00020G00X60Z20N00030T1(外圆右偏刀,副偏角15º)N00040G00X16Z2N00050G24X36W-10F50N00060U-5N00070U-5N00120G00X37Z2N00130G22L2N00140C00U-31N00150G0lW-2F60N00160G03U15.2W-5.5R8N00170G03U4.
怎么刻录((Rufus)系统安装U盘刻录(Linux&Windows)通用方法)
工具或材料:1、工具名字:Rufus2、系统镜像(本文以ubuntu-20.04.2.0-desktop-amd64.iso为例)3、U盘一个(U盘大小大于镜像大小即可)正文&步骤:1、如果下载的是绿色版软件是不需要安装的,直接打开下载的文件后如下图所示2、电脑...
我的锅什么意思(部编初中语文7-9年级下册词语汇编,收藏用三年)
...《邓稼先》元勋yuánxūn:立大功的人(多指开创性的事业中的):开国~。奠基diànjī:奠定建筑物的基础:~石。选聘xuǎnpìn:挑选聘用:~演员。谣言yáoyán:没有事实根据的消息:散布~。背诵bèisòng:凭记忆念出读过的...
手机存放柜编号(广西小伙花2万考驾照,竟是教练发的居然还能“正常”扣分?)
9月12日16时55分许,涂某驾驶粤E牌小型轿车在广州方向374Km处(玉林段)因未与前车保持足以采取紧急制动的安全距离,追尾了檀某驾驶的桂N牌小型普通客车。民警对双方驾驶人车辆和证件进行了盘查,可奇怪的是,经系统查询...
怎么把当贝市场下载到u盘上(微鲸电视如何通过U盘安装第三方软件?当贝市场一招教你搞定)
...要做一下准备工作:打开微鲸电视主页选择【设置】—【通用】,进入后选择【安全】,将【安装未知来源应用】设置为允许,然后从电脑里下载好当贝市场并拷贝到已经格式化的U盘中;然后将U盘连接到微鲸电视USB接口,这时系...
手自一体变速箱是一种结合了手动变速与自动变速功能的变速装置。这一技术是为了提高自动变速箱的经济性和操控性而产生的,能够让由电脑自动决定的换挡时机重新回到驾驶员手中,从而提高驾驶的操作性,丰富驾驶者的体...
民用电话(无人机实名登记UOM系统和通用航空系统发布重要提醒)
关于在实名登记系统修改完善制造人和型号信息的通知尊敬的平台用户:感谢各位无人机设计制造用户对无人驾驶航空器综合管理平台(以下简称UOM)的支持,从2017年民航局建立实名系统以来,为方便无人机用户在实名登记模块...
打开蓝牙(iPhone上车自动播放歌单的快捷指令设置,超简单)
...后选择→“与车载蓝牙连接时”)PS:这一步设置是当你手机开着蓝牙上车后,自动连接上车内蓝牙后,iPhone自动切换成驾驶模式。二:打开系统自带的APP“快捷指令”→选择“创建个人自动化”→在“专注模式”里选择“驾驶...
手机U盘推荐(车载U盘推荐 aigo双口手机U盘 老司机用过都说好)
作为上班族,每天上下班都需要驾车,而一个小时的车程甚是枯燥无味,在碰上堵车更是糟心。所以听听收音机和音乐都是不错的选择,听音乐能使人保存心情愉快,让路怒者平息情绪,还能减少驾驶疲劳。所有老司机有句话,...
...度地防止交通事故的发生。针对以上问题,平安好车主app中的“平安行”和“安全管家”,主要是实现安全风险管理的价值,根据车主的意愿记录和提醒不